

Foreword
“There is nothing regular about Regular Expressions.”
This is not a beginning AutoHotkey book, but a journey into RegEx for AutoHotkey users.
While I've had some experience in past years with Regular Expressions before writing this book, I took on this project as much to learn about how to implement Regular Expressions in AutoHotkey as to teach their use to others. The deeper learning process was not easy and forced me through a number of mental gymnastics. Unlike AutoHotkey programming which almost anyone can quickly understand on a basic level, Regular Expressions require the development of a more complete understanding of the concepts. There are many programmers who do great work, yet they avoid using Regular Expressions. At best they may copy an example from the Web and include it in their own work. The reason for their reluctance comes from how cryptic Regular Expressions appear and the sometimes unusual way they behave.
I started my work with the AutoHotkey RegEx Quick Reference online. It has all the information you need for most Regular Expressions. It is simple and straightforward without any embellishment. If you're an experienced programmer, then that' reference is probably all you will need to get started. But if you're like me, then you will want a little more. There are nuances in Regular Expressions such as the concepts of greed and backreferences which can make writing an expression difficult for those unfamiliar with RegEx engine behavior.
I developed my understanding not by using tutorials, but by working on real AutoHotkey scripts. Eventually, about halfway through the journey, I had an epiphany. I began to grasp the big picture and the true usefulness of the tools—especially the AutoHotkey RegEx functions.To get the most from RegEx in AutoHotkey I had to envision Regular Expressions in their proper role. There are situations when they are the best programming tool, and other times when you're better off using the more standard AutoHotkey commands and functions. The key is knowing when to use them and when other approaches are simpler and will produce better (or quicker) results. That's why this book is not written as a tutorial. Nor do the chapters appear in this book in the order that I experienced and wrote them.
The chapters in the book are grouped by their function in developing a deeper understanding of Regular Expressions while emphasizing the practical application of RegExMatch() and RegExReplace()—the two primary AutoHotkey Regular Expressions functions. I consider the first three chapters (in particular Chapter One and Chapter Three) the most important for getting a quick start on how to view and understand Regular Expressions and the AutoHotkey RegEx functions, most of the remaining chapters can be studied in almost any order as they demonstrate a particular RegEx application—i.e. finding double words in text (Chapter Five); fixing mistyped word contractions (Chapter Six); swapping two word in any text editing (Chapter Seven); extracting IP addresses from text, then extracting the geographic location of each from the Web (Chapter Eight); stripping HTML tags from source code leaving only pure text (Chapter Nine); extracting links from a Web page (Chapter Ten); and validating e-mail addresses (Chapter Eleven). The final two chapters address slightly more advanced, but just as important topic, look-ahead and look-behind assertions, plus RegEx Properties \p{xx}.
There are many Regular Expressions books. (The Regular Expression concept has been around since the 1950's.) But there are not many available which teach RegEx with AutoHotkey. This book assumes that the reader has some familiarity with AutoHotkey, therefore the AutoHotkey commands mentioned (with the exception of the RegEx functions) are not explained in detail. The emphasis in on Regular Expressions more so than AutoHotkey. All the examples in this book are specifically AutoHotkey examples (although they will likely work in almost any programming language with very little alteration).
I use the term "RegEx" as a multipurpose word. "A RegEx" is short for Regular Expression as a general term, but I also use "the RegEx" to mean a specific expression I'm working on. I may also refer to RegEx as the engine which interprets the expressions. The context of the use of RegEx should convey its meaning.
It's possible that you're using this book as a reference while not using AutoHotkey. If you don't use AutoHotkey with a Windows computer, you should. It is the single most powerful scripting language for enhancing your Windows experience. You don't need to be a professional programmer to learn AutoHotkey. The beginning scripts are quite simple to write and implement. There are many resources on the Web for learning AutoHotkey. Give it a shot. You'll be glad you did.
Chapter One: Understanding the Mysteries of Regular Expressions (RegEx) in AutoHotkey
“To Understand How a RegEx Works, It Helps to See Trains Running Down a Track”
Many AutoHotkey script writers don't use Regular Expressions because they seem too mysterious and confusing. All they really need is a little understanding.
Regular Expressions (commonly called RegEx or RegExp) in AutoHotkey is not a beginning level script writing topic and there certainly is nothing regular about Regular Expressions. I've spent a number of months exploring the programming tool and have developed a healthy respect for its flexibility and power. Many (including myself) have avoided using RegEx due to its enigmatic code which at times appears almost incomprehensible. It's not like normal program code with If-Then-Else statements and Loops. Writing a RegEx is not merely a matter of following a logical sequence. It often requires a non-linear look at the problem. I've found that what helps me most is the analogy I picture in my brain pan. That image gives me a basis for what a RegEx is trying to do. ("Try" is a good word when describing RegExs. Whereas the usual programming either works or doesn't work, RegEx "tries" to find
pattern matches. If none are found, it moves on.)
Wikipedia describes a Regular Expression as "a sequence of characters that forms a search pattern, mainly for use in pattern matching with strings, or string matching, i.e. 'find and replace'-like operations." I would describe RegEx as a data mining machine. RegEx is like a train rolling down a track of computer characters looking for patterns which match a specific set of given parameters. If it finds characters which match the pattern set, it grabs them and puts them on board the train.
pattern matches. If none are found, it moves on.)
Wikipedia describes a Regular Expression as "a sequence of characters that forms a search pattern, mainly for use in pattern matching with strings, or string matching, i.e. 'find and replace'-like operations." I would describe RegEx as a data mining machine. RegEx is like a train rolling down a track of computer characters looking for patterns which match a specific set of given parameters. If it finds characters which match the pattern set, it grabs them and puts them on board the train.
As the RegEx train runs down the line, it continues picking up characters—as long as they fit the written instruction set. Some groups of characters may be saved for later reuse (backreferences). At times RegEx may look back at previous characters for validation or forward to coming data for confirmation (backward and forward assertions—see Chapter Twelve). While a particular RegEx may be forgiving in what it will accept on board, if the pattern does not completely match the given set of criteria, the entire group (including all previously collected characters) is kicked off the train and RegEx continues rolling along looking for the another possible set of matching characters. This continues until it either hits the ends of the line or finds a complete solution to its data schedule. Then RegEx stops. The RegEx data mining machine can be started up again by placing it in a Loop which restarts the same search from a point just beyond its current solution.
This data mining train is the image I visualize when working with a RegEx. The key to understanding RegEx is knowing what the conductor is trying to do when it interprets the special symbols in a RegEx set of instructions to bring the right character passengers on board. It took me a while to comprehend that the primary purpose of the AutoHotkey RegEx functions are data extractions, RegExMatch(), or data correction, RegExReplace() as discussed in Chapter Three.
Practical RegEx Uses
Maybe the most important question is, "If Regular Expressions can be so confusing, why bother?" Often when doing simple text searches or replacements it's quicker and easier to use functions built into a language. RegEx may be adding needless complication. However, a RegEx might do with one expression what takes several lines of code when using those other functions. It may take slightly longer to complete (a few more microseconds), but the added flexibility could make the seemingly impossible a reality. RegEx has more power and flexibility than a standard search and/or replace.
For example, IP addresses are many and varied—although they all conform to the same pattern. Each IP consists of four numbers (one to three digits long and between zero and 255) separated by a dot. With the proper RegEx, the engine can search through a document pulling out only the IP addresses. Then those extracted addresses can be used to find where the IP is located. AutoHotkey with RegEx creates a Web IP lookup app finding extracted IP address locations throughout the world.
Another use for a RegEx may be to find duplicate words in a document. This can be done with other functions, but it would take a few lines of code with conditionals (If-Then), whereas only one RegEx line is needed. How about swapping the first and last words in selected text?
Maybe you want to strip all of the HTML code out of a Web page leaving only the text? Or, possibly you need to extract a list of all of the Web links found in a Web page? RegExs are the best way to ensure that a properly formatted, valid e-mail address is entered into a data field.
Pulling the numbers out of alphanumeric data is relatively simple with RegEx. Or, maybe a key symbol (escape character) needs to be inserted in front of (or behind) each of a group of special characters.
If it's a pattern you need to find (and possibly manipulate) in your haystack of data, then RegEx may be your best bet. This may be all the incentive you need to explore the mysteries of Regular Expressions.
RegEx History
While not critical to understanding how to use Regular Expressions, knowing how such a strange programming animal came into being helps to develop a proper appreciation for it. The seeds of RegEx actually predate the first computer in mathematical recursion theory which "originated in the 1930s, with work of Kurt G?del, Alonzo Church, Alan Turing, Stephen Kleene and Emil Post." But it wasn't until 1956 when Stephen Kleene first "described regular languages using his mathematical notation called regular sets." At this time, while computers did exist and were in use, they were still in their infancy.
In the late sixties, Regular Expressions came into popular use primarily in text editors. " Ken Thompson built Kleene's notation into the editor QED as a means to match patterns in text files." Two decades later, the pattern matching techniques in a more advanced RegEx library written by Henry Spencer became part of the Perl programming language. "Starting in 1997, Philip Hazel developed PCRE (Perl Compatible Regular Expressions), which attempts to closely mimic Perl's regular expression functionality…" PCRE is now considered the standard for RegEx engine implementation.
The major programming languages now either include a RegEx engine or a library implementation. While it may vary slightly, the symbolic coding is based upon PCRE. The AutoHotkey scripting language is no exception and supports most of the same syntax and symbols as other implementation. Usually example expressions found on the Web for other languages can be used directly in AutoHotkey.
There are a couple of RegEx symbols named after the mathematician Stephen Kleene. You may be familiar with the commonly used search and pattern match wildcard symbol * which is called the Kleene star. It's used to match none or more of a set of characters. In most computer uses we tend to use asterisk (*) to mean any character, but in a RegEx it applies to a previously matched set of characters while the dot (.) is the wildcard for any character. The Kleene plus + is similar to the star, but is used to match one or more, rather than none or more.
RegEx in AutoHotkey
There are two primary RegEx functions in AutoHotkey: RegExMatch() and RegExReplace(). While working with both over the past few months, it slowly dawned on me when to use each one. While there is some overlap, the two functions have distinctly different powers.
RegExMatch() is an extraction tool for finding and saving specific matches within the haystack of data. Once RegEx finds a match and extracts the data, the RegEx train stops in place. If you want it to keep going and find more matches to extract, then the function must be put inside a Loop and restarted at its previous stopping point. RegExMatch() does not affect the original data while collecting matching data.
RegExReplace() is an alteration tool rearranging data as the train runs down the line. It finds a match, then replaces it with the appropriate changes. Unlike RegExMatch(), by default, RegExReplace() does not stop upon finding a match. In fact, unless told otherwise, the RegEx train continues locating the pattern and making changes until it reaches the end of the haystack.
Understanding the differences in these AutoHotkey functions makes it easier to pick the proper tool for the job. RegExMatch() is for mining, extracting, and replicating data ore for use elsewhere, while RegExReplace() is for changing and rearranging the ore inside the data mine. The difference between these two AutoHotkey functions and when to use them (with examples) is discussed in more detail in Chapter Three.
The Best Way to Learn Regular Expressions
While I've read a good bit about RegEx, reading about them alone is not the best way to learn. There is no substitute for writing an expression, then watching its effect. While there are many examples available either throughout these chapters or on the Web, actually using one in an application will provide infinitely more insight into how they work. For AutoHotkey, I've found that Robert Ryan's Regular Expression Testing App is invaluable.
Ryan's Regular Expression Testing App
When I started working with RegEx, I was writing tiny AutoHotkey scripts, testing my attempts, then making changes and testing again…and again., Eventually, I checked the AutoHotkey Scripts Forum and found this Regular Expression Tester written by Robert Ryan (see Figure 1). It's pretty slick, saves a lot of time, and offers instant understanding into how RegEx works.
It needs to be noted that the RegEx Tester script was written for AutoHotkey_L and won't work with the Basic version of AutoHotkey. However, AutoHotkey_L is the currently accepted version of AutoHotkey and the download available on the site. Also, this RegEx tester was written for Perl Regular Expressions. While almost everything is identical when used with the AutoHotkey RegEx functions, there is one important difference. Since the functions delimit the RegEx with double quote marks, any double quote mark within the RegEx itself must be escaped with another double-quote ("") when used inside the AutoHotkey functions.

Figure 1. Ryan's Regular Expression Tester is used to evaluate the e-mail address validating expression used by the ComputorEdge E-mail Subscription Form.
This RegEx tester is interactive and immediately updates as either the input text data or expression is changed. For matching expressions (RegExMatch()—the first tab) the search string is entered into the top edit box. The RegEx is entered into the second edit box and the start character is entered into the next edit box (default is the first character). The results appear in the text box at the bottom of the window.
If the RegEx works and a match is found, then the Results box will show the match plus any subpattern matches (Match[1], Match[2], and Match[3]). If the RegEx fails to find a match, then FoundPos is 0 and Match is blank. The beauty of this tester is that you can change the data and instantly see if the RegEx is accepting or rejecting the data format or if there is a problem with the expression.
The same is true for the RegExReplace tab which replicates the RegExReplace() function. The data string in entered into the top text box, then the RegEx (without double quotes) in the second box, and the Replacement Text in the following box. The altered string appears in the bottom box. Making minor changes to the input text and/or the expression and replacement text can give you tremendous insight into how RegEx works. It did for me!
In the course of writing the many AutoHotkey RegEx chapters I've used Ryan's Regular Expression Tester extensively and must give credit and pay homage to Robert Ryan who wrote the script. I've never met or communicated with him, but have benefited from his brilliance and one of the most useful programming tools I've found. Not only was I able to test my own expressions, but I was often able to change and simplify them based upon the instant feedback the Regular Expression Tester provided. Thanks, Robert! Wherever you are!
Chapter Two: An Introduction to Easy Regular Expressions (RegEx) in AutoHotkey
“A quick guide to understanding how Regular Expressions (RegEx) work in AutoHotkey.”
Regular Expressions (RegEx) are notorious for driving people insane, but taken a little at a time they can be simple.
In this book, I'm tackling the subject of Regular Expressions (RegEx or RegExp) in AutoHotkey. While I have had some experience with RegEx over the years (primarily Javascript), I'm by no means an expert. That means I needed to review a considerable number of references and play with different problems before I started to truly understand the secrets they hide. (RegEx does not actually have any secrets, it's just that the coding can be so enigmatic that it looks like a foreign language—regardless of your native tongue.) Looking at any RegEx, no matter how simple, can leave a person bewildered. Plus, many RegEx lines get long and and may appear convoluted. There must be an easy way to understand how they work.
My goal in this book is to give enough insight into how RegEx works that it becomes a little easier to write and decipher one. Once understood they become much simpler to use. Plus, it's important to understand when they are most useful and how to implement them in AutoHotkey.
Why RegEx?
The number one reason for learning RegEx is that it is possible to do quite complex matching of strings of text with one line of code. The powerful options and wildcards used in the expressions can search through loads of text and files to find data which fit very specific, yet flexible, criteria. When using the AutoHotkey RegEx functions, once we find matching data, we can either extract the data, RegExMatch(), or change it, RegExReplace(). Each of these powerful functions has its own best time and place for use in an AutoHotkey script (which is the subject of Chapter Three).
On the downside, those same RegEx options and wildcards look cryptic and confusing. While it is easy to get started with simple examples, it can quickly become befuddling. There is no substitute for actually doing it, although you can often find pre-built RegExs which you can immediately put to work by inserting them into your AutoHotkey scripts. For example, the following AutoHotkey function determines if an e-mail address is formatted properly:
FoundPos := RegExMatch(Haystack, "^\w+([.-]?\w+)*@\w+([.-]?\w+)*(\.\w{2,4})$", newvariable)
If you plug this expression into an AutoHotkey script (without knowing how it does it), it will tell you whether someone has inputted a properly formatted e-mail address into an AutoHotkey app or if it is a fake. (Discussed in Chapter Eleven.)
The code found between the double quote marks is the RegEx code. No wonder so many people give up before they start. However, after reading this chapter, you should be able to understand most (not all) of the code in the expression.
RegEx in AutoHotkey
I started this RegEx journey while working to resolve an issue in my Calorie Count script where I would accidentally enter a comma into a number field of an AutoHotkey GUI window rather than a decimal point. If I inadvertently used a comma, a built in calculation stopped working since the value was no longer recognized as a number. In one ComputorEdge AutoHotkey column, I addressed some non-RegEx methods for insuring that the number of servings in the Calorie Count script was actually a valid number so that the total number of calories would calculate properly. The problem was that the comma key when accidentally hit (it sits right next to the decimal point key) turned the number into a text string. While I did solve that problem without RegEx by automatically replacing any commas with a decimal point, the same thing could occur with any other non-numeric character inadvertently keyed in. I decided it was time to explore Regular Expressions to solve this number validation problem.
At the time I immediately dug into the validation problem in the Calorie Count app, but my shallow understanding of the AutoHotkey RegEx functions caused me to venture down some unneeded paths. When putting together this book, I reorganized the order of the chapters and updated them to reflect my insights and better explain how to use RegEx in AutoHotkey while building a better understanding of the RegEx world—regardless of the programming language. The original Calorie Count RegEx project is discussed in Chapter Four—including all of my missteps. But first we need to better understand the mechanics of how RegEx works.
The Mechanics of RegEx
Critical to using a RegEx is understanding how it works. RegEx is a system for finding matches within strings (text) which may be file names, variables, or the contents of a file. (Such a search string is called the "Haystack" in the online documentation for the AutoHotkey Regex functions, while the search expression is called the "NeedleRegEx"—as in "needle in a haystack."). In the original Dictionary script found on the Free AutoHotkey Scripts and Apps page, a fairly complex RegEx was used to parse the definitions from the Dictionary.com Web page. It did this by matching certain text or code within the page source code and returning the results to a pop-up window. While I was stupefied by the complications in that particular RegEx, I'm sure that with a little time I could have figured it out. The key is understanding that the primary function of a RegEx is to find matches to the "needle in the haystack."
Knowing what a RegEx will actually do depends on how well you understand what it is trying to do. A RegEx starts at the beginning of a string and looks at each character one by one until if finds a match for the entire expression. If it finds a match (NeedleRegEx) it stops looking, otherwise it continues until it reaches the end of the input string (Haystack). In AutoHotkey the function used for matching a RegEx is RegExMatch() which returns the numeric location of the first character of first occurrence of a match. (A numeric location is found by counting the number of characters from the beginning of the Haystack to the first character in the NeedleRegEx.)
For example, in its simplest form the NeedleRegEx might be a lowercase a (or any other letter, number, or character). The RegEx engine will search the Haystack looking for an a. If found, it stops and returns the location of the letter:
FoundPos := RegExMatch(Haystack, "a")
FoundPos is the location of the first occurrence and Haystack is the input string. Note that the RegEx itself (a the needle we want to find) appears within double quotes. If Haystack is "the quick brown fox jumped over the lazy dog" the a in "lazy" is found at position number 38 (FoundPos) (or the 38th character in the string including spaces). If there is no a in Haystack, the needle is not matched and FoundPos returns 0 (zero).
To make the RegEx slightly more complicated we add another character to our RegEx:
FoundPos := RegExMatch(Haystack, "ab")
Now our needle in the Haystack is the ab letter combination. RegEx will again look for the letter a until it finds a match. Only then will it look at the letter "b" for a match of the next character. If there is no following "b" then it drops everything and continues looking for the next "a" again. For example, if Haystack is "Abby has always been absent from the abbey", then FoundPos is 22.
What? That FoundPos coincides with the "ab" in "absent", not the first "ab" in "Abby." This brings us to an important concept—RegEx is case sensitive. If you want to find a capital letter, it better be capitalized in the RegEx. The word "Abby" in the haystack is skipped as a match because the "A" is uppercase while the needle is "a" lowercase.
Note: There is an option to make the RegEx case insensitive, but that will be left for another chapter. That's the problem with RegEx. There are so many possibilities and options that it's easy to get confused.
As RegEx moves through the Haystack it stops at each letter "a", then checks for a letter "b" immediately following it, but none are found until reaching the word "absent" starting at position 22. Having found a complete match, RegExMatch() stops.
This is the essence of how RegEx works. If more characters are added to the expression's NeedleRegEx, then more is required to find a match. However, in the problem of validating numbers (for example in the Calorie Count app originally discussed in the book AutoHotkey Applications) the digits can be any numbers, but no letters.
Using Ranges in RegEx Matches
The simple way to match any number in the RegEx is to give a range of options. This is done by enclosing all the optional characters within square brackets […]. For example, placing all the vowels within square brackets makes each one a possible match:
FoundPos := RegExMatch(Haystack, "c[aeiou]t")
This function would return FoundPos for "cat", "cot", or "cut"—whichever one is found first. Proceeding through the Haystack, the RegEx engine stops at each occurrence of the letter "c", then tries to match the next character with either "a", "e", "i", "o", or "u", but no other character. If one of those options is not found, the search continues looking for another "c" character. If found, the vowels are checked again. If there is a match, the third character is checked to see if it is the "t" character. If yes, the RegEx engine stops searching and returns the location of the "c" character. If no, it continues moving down the Haystack until it either finds a complete match or reaches the end of the line.
In our situation we want to use the numeric digits [0123456789]. (The order of the digits inside of the square brackets doesn't matter.) If we wanted to match two digits in a row then [0123456789][0123456789] would do the job. The problem is that we don't know how many digits in a row we need to match. It could be one, two, three or more—at least theoretically. At those times when you don't know how many characters will occur in a row, rather than repeating the range for each matching character, adding the plus + sign after the range (or character) will do the job:
FoundPos := RegExMatch(Haystack, "[0123456789]+")
This RegEx search function will match one or more digits in a row until a non-digit is encountered—returning the location of the first digit in FoundPos.
Tip: Ranges of numbers or letters can be shortened by using a hyphen. For example, [0-9] is the same as [0123456789]. [A-Z] is the same as all capital letters while [a-z] is all lowercase letters. All letters and digits can be represented by [a-zA-Z0-9]. To shorten the expression for the numeric digit range even more use \d in place of [0-9]. Our shortened function becomes:
FoundPos := RegExMatch(Haystack, "\d+")
This will match one or more numeric digits in a row.
Adding the Decimal Point and Saving the Result to a Variable
There is a decent possibility that our number of servings in the Calorie Count script will include a decimal point indicating fractions of a serving. That means we need to allow one to match in the RegEx. The simplest way to do this is include one in the range:
FoundPos := RegExMatch(Haystack, "[\d.]+")
The plus + sign after the range makes the RegEx match one or more occurrences of any numerical digit plus the decimal point.
RegEx Tip: To add to the confusion, the dot (.) used inside a range […] does not have the same meaning as the usual RegEx dot when not inside a range. Outside of a range, the dot . is a powerful wildcard representing any character whereas inside the square brackets it is merely a period or decimal point. Outside a range, if you want only a dot, period, or decimal point, then you must precede it with a backslash "\." in the RegEx. (The backslash \ is the escape character for removing magical properties from special RegEx characters or adding special meaning to normal characters, as in \d above.) As you learn more about Regular Expressions, you'll find that a number of characters—particularly the question mark (?)—have different meanings when used in different situations. Be patient and you'll eventually find that this all make sense.
The RegExMatch function includes a feature for saving any matches to a variable by adding the new variable name:
FoundPos := RegExMatch(Haystack, "[\d.]+", newvariable)
This is great since otherwise it would be necessary to parse the string. The new string can be returned to the Number Servings field with the GuiControl command (GuiControl, ,Food5, %newvalue%), thus eliminating any non-numeric characters. The one problem with this expression is that multiple decimal points are allowed in the result. I tried a number of other variations, but this was by far the simplest—although I need to figure out how to eliminate any excess decimal points.
Note: This is a very basic introduction of how RegEx works which introduces a couple of the special symbols. The majority of this book uses specific AutoHotkey examples to add more of the inner workings and hidden mechanism involved in developing working Regular Expressions. When I started my learning process I used the short AutoHotkey script with follows to test my expressions. However, once I came across Ryan's RegEx Tester (also written in AutoHotkey), I switched over to it. Most of the chapters stand on their own and are not necessarily in the order that I did my own learning. I have grouped the chapters in this book based upon my own understanding of RegEx and the concepts which slowly determined my view of how to work with them.
One of the best ways to learn how RegEx works is to test a few. You can write your own little AutoHotkey test script to actually see the effect of the various RegEx options:
Haystack := "Abby has always been absent from the abbey."
FoundPos := RegExMatch(Haystack, "ab.*t", newvariable)
MsgBox %FoundPos% %newvariable%
FoundPos := RegExMatch(Haystack, "ab.*t", newvariable)
MsgBox %FoundPos% %newvariable%
While the explanations are helpful in the documentation, there is no substitute for actually seeing how they work. (In this example the dot . is a wildcard followed by the asterisk *. The asterisk * is similar to the plus sign +, except it means repeat the preceding character none or more times rather than one or more times.)
There are a number of other special characters which affect the behaviour of the RegEx discussed in many of the following chapters. The question mark ? when following a character or range means the preceding character is optional—match none or one time. The pipe (a horizontal line inside a range [… |…]) means match either from the range before the pipe | or the range after the pipe | symbol. The \w symbol is similar to \d except it means match any letters (upper or lower case) or digits. The symbol \w is the same as [A-Za-z0-9]. These are merely a few of the more common symbols. As you continue you'll find techniques for matching a negative (matches only if it is not a specific character or set of characters), matching the beginning and end or the haystack (anchors), and more. Many times the same symbol is used for different purposes—in particular ? and ^ have different meanings depending upon where they are used. Once you understand each use, the Regular Expressions should generally be easy to decipher.
Don't be impatient. It takes time to learn the nuances of Regular Expressions. While reading the AutoHotkey RegEx Quick Reference Guide is useful, only writing and testing one yourself will help you comprehend how a RegEx actually does its job.
In Chapter Four, I look at ways to clean up the formatting in the RegEx validated number field and discuss more AutoHotkey RegEx features while working on the Calorie Count app found in the AutoHotkey Applications book. But if you're not familiar with those Calorie Count discussions, then you may be better served either skimming or skipping Chapter Four and jump to the techniques most relevant to you.
But first, it is worthwhile to investigate the differences between the AutoHotkey RegExMatch() and RegExReplace() functions and in which situations each is best used. That's the purpose of the next chapter—"Chapter Three: AutoHotkey RegExMatch() Versus RegExReplace()."
Chapter Three: AutoHotkey RegExMatch() Versus RegExReplace()
“AutoHotkey Regular Expression functions (RegEx) can make complex text extractions and replacements easy.”
Although RegEx in AutoHotkey can be confusing, it's worth the time to learn how to use the functions RegExMatch() and RegExReplace() for the power they deliver to your scripts.
In AutoHotkey there are two primary functions used with Regular Expressions: RegExMatch() and RegExReplace(). Half the battle of using RegEx functions in your scripts is knowing when to use which one. They both will save results to new variables and use the same expressions to find matches, but what each function does best is very different.
RegExMatch() Versus RegExReplace()
When comparing RegExMatch() and RegExReplace(), there are important differences. In order to properly use RegExMatch() or RegExReplace() in an AutoHotkey script, we need to understand how each function behaves.
First, RegExMatch() only finds the first match for the RegEx then stops in its tracks. Unless told otherwise, this function starts at the beginning of the input string and continues down the line until if finds a match. It will ignore the remainder of the string. The only way to get RegExMatch() going again is to restart it by reissuing the command. This is usually done by placing the command in a Loop and adjusting the StartingPosition to a location past the last match found.
FoundPos := RegExMatch(Haystack, NeedleRegEx [, UnquotedOutputVar = "", StartingPosition = 1])
In contrast, RegExReplace() is a much hungrier function. Once started, by default, it will continue through the entire string finding (and altering) matches until it reaches the end of the line. In fact, if you don't want the function to process the entire input Haystack, then you must Limit it to the number of match replacements you want completed.
NewStr := RegExReplace(Haystack, NeedleRegEx
[, Replacement = "", OutputVarCount = "", Limit = -1, StartingPosition = 1])
[, Replacement = "", OutputVarCount = "", Limit = -1, StartingPosition = 1])
Next, RegExMatch() tells you where you will find the match in the Haystack. The value returned for the function is the starting position of the match (or 0 if no match is found). By default, it doesn't even tell you the length of the matching string. If you want to save the data, you must supply a variable name (UnquotedOutputVar) within the function. Then, RegExMatch() will create the new variable along with additional pseudo-array variables for any subpatterns. If the proper options are applied to the RegEx, the position and length of the total match and each subpattern can be saved.
As might be expected RegExReplace() directly returns the entire new altered string. This makes it ideal for mass replacement similar to those done with the AutoHotkey StringReplace command. StringReplace is faster than the RegExReplace() function, but it doesn't have the flexibility and power of Regular Expressions. The RegExReplace() function has the power to alter the text by replacing it and returning the new string in a variable. This is useful for situations where there may be a number of conditions which require replacement, such as when matching characters vary.
To know when to use which function it's important to understand that RegExMatch() is used for either extracting a match for later use or validating data to make sure it is in the correct format. RegExReplace() is used for either changing the format of matching data or correcting data input on the fly.
RegExMatch() for Data Validation
One of the most common uses of Regular Expressions is the validation of data when it is typed in by a user. E-mail addresses, acceptable passwords, telephone numbers, IP addresses, and other information which requires a specific format are good examples. The user enters the data and attempts to move on. If the format does not match, the computer immediately tells the user and returns focus to that field. Validation is ideal for the RegExMatch() function. If the format is valid, the function returns a positive value. If false, it returns 0.
In Chapter One, I give an example of how to use RegEx Tester to analyze a RegEx using the RegExMatch() function. In that case it was an expression used for validating an e-mail address. If an address doesn't match the RegEx format, it is rejected as a bad address.
In Chapter Four, RegExMatch() is used to ensure that the number of servings in the Calorie Count app is actually a number. Otherwise the automatic calculation of total calories will not work.
In the CalorieCount script (Chapter Four), I use the following to remove all non-numeric characters except the decimal point from a variable:
NewValue := RegExReplace(Food5, "[^\d.]", "") ;remove letters
(While the StringReplace command is faster it doesn't have the flexibility of RegExReplace()). In the above expression the numeric digit wildcard (\d) is placed inside a range ([]) with the decimal point (.). The caret (^) when placed inside the range tells RegEx to match anything that is not in the range—not a numeric digit or decimal point. The effect is any non-numbers entered into the variable editing field are automatically removed. This would be tedious with the StringReplace command.
[Chapter Four Confession: The validation of the Number of Serving in the Calorie Count app was one of the first AutoHotkey RegEx tasks I undertook. I didn't have a deep enough understanding of the two functions and when to use each. I unnecessarily started out with RegExReplace() and ended up appropriately with RegExMatch(). I went down a couple of dead-ends. While the explanations are valid and useful, I was tempted to leave the chapter out of this book. However, there are a number of learning points included which are worthwhile as long as you don't assume that it demonstrates the best way to solve the problem. Knowing what I know now, if I were to do again, I would probably have a different solution. In fact, a better overall solution to validating numbers now appears at the end of that chapter.]
Chapter Eleven discusses how to use AutoHotkey to validate an e-mail address with RegExMatch() by making sure that an e-mail address is in the correct format. It returns 1 and the e-mail address when it is valid and 0 when it is not (see Figure 1).

Figure 1. If the e-mail validation routine works, the message box displays the address. If not, the message box displays zero.
This matching technique can be used with any other type of data which requires a specific format. If you are creating a form with a number of fields, it's helpful to the user to check the entries and eliminate mistakes.
RegExMatch() for Extracting Data
But validation may not be the most important use for RegExMatch() in AutoHotkey. It took me a little while to grasp that RegExMatch() is an excellent data mining tool. If you encounter a mass of data and need to extract a particular piece of it, then this is the tool to use.
The biggest mass of data we find today is the Internet and its many Web pages. Writing apps which bypass the Web browser and go directly to a Web page extracting useful data is one of AutoHotkey's strengths. It's faster than opening a Web browser, goes directly to the data source, and, since it mines behind the scenes, saves the time needed to visually search through a Web page. The uses for this type of techniques are only limited by the number of topics addressed by all Web pages on the Internet.
In Chapter Eight an AutoHotkey app is demonstrated which extracts all the IP addresses in any highlighted section (in any Windows program) and looks up the geographic location for each (see Figure 2). RegExMatch() is used twice: First to extract all the IP addresses from the highlighted text; second to extract each IP location from the source code of a Web page.

Figure 2. IP addresses are extracted from highlighted text, looked up on the Internet, then displaying their geographic locations.
I use this little AutoHotkey IP finding app on a regular basis. I get a number of PayPal orders at ComputorEdge E-Books which give no address—only an IP address. While I can't see the street address, with this script I can find where in the world the buyer is located.
Sometime you come across a Web page which is filled with useful links. It would be great to save the link list in a file without all of the extra text and formatting. It's tedious to copy links one at a time. In Chapter Ten an AutoHotkey script which extracts a list of all Web links embedded in a Web page is demonstrated (see Figure 3).

Figure 3. The extracted links are written to a text file then opened with Notepad.
In this AutoHotkey script, RegExMatch() uses the special formatting in the HTML source code for the Web page to identify and extract Web links, then list them in a text file. This technique is useful for virtually any type of data in any Web page or other document source.
Another Use for RegExMatch()
In a effort to show the practicality of RegEx in AutoHotkey, I'm always on the lookout for ways to improve a script. I was on the AutoHotkey Forum interacting with someone who wanted to parse a number out of the title of a window. He needed the number to match a condition. He finally settled upon:
StringTrimLeft, window, window, 69 ;deletes 69 characters from the left of what the variable holds *
StringTrimRight, window, window, 43 ;deletes 43 characters from the right of what the variable holds *
StringTrimRight, window, window, 43 ;deletes 43 characters from the right of what the variable holds *
for removing a specific number of characters from both sides. He could have done it in one line with RegExMatch():
FoundPos := RegExMatch(window, "\d+" , window)
This yields the same result (any digits found in a row), but you wouldn't need to know how many characters to trim front and back. This assumes that there are no other digits appearing in the title before your target numeric string. FoundPos returns the starting point of the number in the string and is probably not needed.
RegExReplace() for Correcting Data
The StringReplace command is fast for making changes in text, but the RegExReplace() function gives much more flexibility by finding a greater variety of matches while making corrections. RegExReplace() doesn't need to know the exact string, but only parameters which will find a match.
For example in Chapter Five RegExReplace() finds duplicate words which appear next to each other within any section of text (e.g. "and and" or "the the"). In most cases this is an error, but occasionally it is deliberate. ("What is it you do do?) This is done by checking every word in the text to see if it matches the following word. If so, the words are marked with a special character for later review and correction. The script could just as easily be set up to automatically delete the second word which would eliminate all uses of double words—even if appropriate.
Another example of a text correction is when any punctuation other than the apostrophe is found in a contraction. Chapter Six gives a technique for using the RegExReplace() function to find the errors in a variety of contractions—fixing them by replacing the errant character with the apostrophe. This technique is valuable whenever there is a consistent way to correct a repetitive error.
RegExReplace() for Reformatting Data
Possibly more useful is how RegExReplace() and be used to change or reformat data. The function can combine a number of programming steps into one line while searching for and changing a variety of data formats.
In Chapter Seven RegExReplace() is used to swap the first and last word in a selected section of text ("butter and bread" is corrected to "bread and butter"). The script doesn't need to know what the words are, only that you want to swap the first and last word.
Suppose you want to strip all of the HTML tags out of the source code for a Web page to get a clean copy of the text. Chapter Nine uses RegExReplace() to find (see Figure 4) all of the tags in the source code, then removes them.

Figure 4. When viewing the source code the HTML tags are seen.
Using RegExReplace() to Add AutoHotkey Escape Characters
Another usage of RegExReplace() could be to clean up text before employing it it in an AutoHotkey app. Certain special characters (,%`;) need to be escaped with the tick mark (`) for them to be read as the raw symbol. You can use StringReplace to deal with the problem by running it four times or do it in one pass with RegExReplace(). If Robert Ryan's RegEx Tester is used, we can see how RegEx can be used to escape each of the special characters (see Figure 5).

Figure 5. The RegReplace tab of the RegEx Tester shows the results of using the RegExReplace() function to insert the escape character (`) before special AutoHotkey symbols.
In Ryan's RegEx Tester the RegExReplace tab is selected showing the target text in the top box. I enter each of the special characters separated by the first few letters of the alphabet. If the RegEx works then a tick mark should be place in front of each of the special characters (,%`;) leaving the letters untouched. The expression used is simply ([,%`;]) which matches each of the characters in a range of options (square brackets) and encloses the entire expression in parentheses creating a subpattern which can be used as a backreference for the purpose of substitution each time one of the special characters is found in the text string.
The replacement text uses the $1 to indicate that the first subpattern found is the backreference and will be part of the replacement. If there is more than one set of parentheses, then the backreferences are numbered consecutively ($1, $2, $3,…). To use the entire RegEx, enter $0 as the backreference. (Note that the replacement text is not a RegEx, although there are a couple of options, such as the backreference notation, available.) Now each of the special characters have the escape character tick (`) placed in front of it by adding the tick to the replacement text (`$1). The Results window in Figure 1 shows the output which has inserted the tick in front of each of the special characters in the range. During the scan of the string, each time one of these characters is encountered in the string, it is replaced with both the tick mark and itself—as indicated by the backreference ($1).
This type of RegEx replacement is a powerful tool for manipulating data. It can match patterns, capture data, and rewrite variables to suit the situation. It may be used to rename files in a folder in a predetermined format or parse out data in the source code of a Web page. I have no doubt that if someone were to make the proper adjustments to the RegExs in the currently inoperable Dictionary script found at the ComputorEdge AutoHotkey download site, then it could be repaired—at least until Dictionary.com changes its formatting again. (You can get your own free Dropbox account with 2 GB of space.) Adding the backreference feature to RegExReplace() opens many new possibilities for any search and replace.
RegExReplace() is a valuable AutoHotkey tool for text (or number) correction and text reformatting. The better you understand how it works, the easier it is to know when to use it.
AutoHotkey RegEx Function Tips
You can find many RegEx examples on the Web written for other language. Usually, it's pretty easy to recognized what can be used from the example. I've found that the most common change needed is when an expression contains a double quote ("). In a RegEx function, which already encloses the entire expression with double quotes, any double quote must be escaped by preceding the double quote within the expression with another double quote. This is a common error.
For example, if Ryan's RegEx Tester is used to develop the expression, it does not require any special treatment of a double quote within the tested expression. However, when copying that that RegEx to one of the AutoHotkey RegEx functions, any double quote will need another double quote added before it. Otherwise the expression will fail.
You may also find that other Regular Expressions examples found on the Web are enclosed with curly brackets, e.g. {expression}, or forward slashes, e.g. /expression/. When borrowing one of these examples for use in an AutoHotkey RegEx function, merely replace the delimiters with the usual double quotes, e.g. "expression", used in the AutoHotkey functions.
Chapter Four: Simplified Regular Expressions in AutoHotkey
“More Regular Expression Tricks with Numbers for AutoHotkey Validation”
This time there are more simple examples of how to use RegEx functions to manipulate data in AutoHotkey.
In this chapter, I look at ways to clean up the formatting in the RegEx validated number field and discuss more AutoHotkey RegEx features while working on the Calorie Count app. I wrote this chapter early on in my RegEx learning process. As I reread the chapter, I realized that for people unfamiliar with the Calorie Count app discussed in my book AutoHotkey Applications it could be confusing rather than clarifying. I considered eliminating the chapter from the book, but there are a number of useful techniques offered here which may come in handy later.
But if you're not familiar with the previous Calorie Count discussions, then you may be better served either skimming this chapter for the for the specific RegEx techniques to add to your toolbox. Then, jump to the end of this chapter, "A Learning Experience with an Improved Solution," which bypasses many of my early wanderings and offers a simpler RegEx for validating numbers with decimal points.
* * *
I continue digging into Regular Expressions (RegEx) in AutoHotkey. In Chapter Two, I gave a short, simplified tutorial on what RegEx does and how it works. The power of RegEx comes from the many things that it can do when searching for matching strings. This variety of options is also the source of confusion which causes many people to give up. By taking only a little at a time to work with the Regular Expressions language, it's much easier to see how RegEx does its job.
As an example for this chapter, I'm using the Number of Servings field in the Calorie Count script which has occasionally caused me problems. When multiplied by the Calories/Serving it yields the total number of calories for any given food (see Figure 1). The problem is that whenever I accidentally enter a comma rather than a decimal point the automatic calculation stops working because the new value is no longer a number. (The comma sits right next to the decimal point on the keyboard and I rarely use the number keypad.)

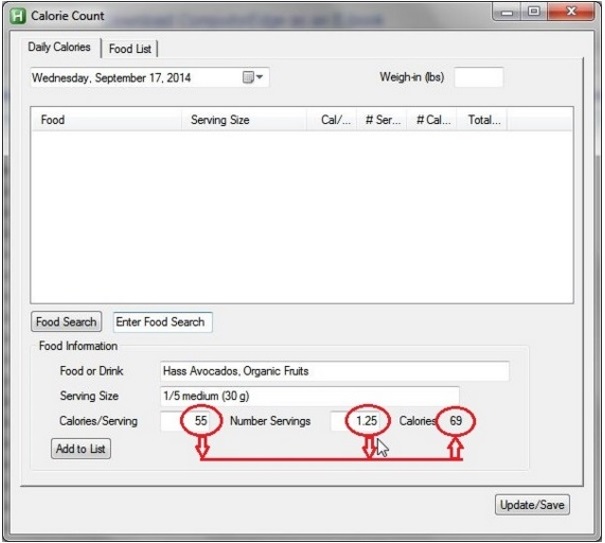
Figure 1. Using Calories/Serving and Number of Calories, the total number of calories for a food item is calculated.
I looked for a built-in solution such as the Number option available in the Gui, Add, Edit command. When the Number option is added only digits can be entered into the field (see Figure 2)—not even a decimal point will be accepted. This works fine for Calories/Serving since it is an integer and doesn't need a decimal point available. But, when the Number Servings edit field must accept a fraction of a serving, the Number option is useless.

Figure 2. When using the "Number" option in the Calories/Serving field only digits can be entered.
In an earlier attempt, I used a partial fix which would change the accidental comma into a decimal point. While this worked, it still allowed the entry of other characters which could cause the same problem with the calculation. I decided to investigate using RegEx to solve the problem. The goal was to validate the Number of Servings field so that only a number (with or without a decimal point) can be entered. This would eliminate the accidental keys and commas from the result. I don't know that I found the best solution, but it works. The new TotalCalCalc subroutine includes a number of uses of the AutoHotkey functions RegExMatch() and one of RegExReplace():
TotalCalCalc: ;Calculate total calories
Gui, Submit, NoHide
StringReplace, Food5, Food5,`,,.,all ; turn commas into decimals
NewValue := RegExReplace(Food5, "[a-zA-Z]", "") ; remove letters
NewStr := RegExMatch(NewValue, "[\d.]+", NewValue) ; match all numbers and decimals
SetFormat, float, 5.2 ; set number format to two decimal places
NewValue += 0 ; forces the variable to be a number
NewStr := RegExMatch(NewValue, "\.00$") ; detect double zeros after decimal
If NewStr ; remove double zeros after decimal
NewValue := SubStr(NewValue, 1 , NewStr)
NewStr := RegExMatch(NewValue, "\..0$") ; detect single zero at end
If NewStr ; remove single zero
NewValue := SubStr(NewValue, 1 , NewStr+1)
GuiControl, ,Food5, %newvalue% ; update value of Number Servings
SendInput, {End} ; place cursor at the end of the field
TotalCalVal := Round(Food4 * Food5)
GuiControl, ,Food6, %TotalCalVal%
Return
Gui, Submit, NoHide
StringReplace, Food5, Food5,`,,.,all ; turn commas into decimals
NewValue := RegExReplace(Food5, "[a-zA-Z]", "") ; remove letters
NewStr := RegExMatch(NewValue, "[\d.]+", NewValue) ; match all numbers and decimals
SetFormat, float, 5.2 ; set number format to two decimal places
NewValue += 0 ; forces the variable to be a number
NewStr := RegExMatch(NewValue, "\.00$") ; detect double zeros after decimal
If NewStr ; remove double zeros after decimal
NewValue := SubStr(NewValue, 1 , NewStr)
NewStr := RegExMatch(NewValue, "\..0$") ; detect single zero at end
If NewStr ; remove single zero
NewValue := SubStr(NewValue, 1 , NewStr+1)
GuiControl, ,Food5, %newvalue% ; update value of Number Servings
SendInput, {End} ; place cursor at the end of the field
TotalCalVal := Round(Food4 * Food5)
GuiControl, ,Food6, %TotalCalVal%
Return
It's pretty long compared to the original label (subroutine), but it illustrates a few ways that RegEx can be used in AutoHotkey without making the RegEx expressions too complicated. Remember that TotalCalCalc activates every time there is a change in either the Calories/Serving field or Number Calories field to recalculate the total Calories seen in text field on the right side.
The first line encountered after the Gui, Submit, NoHide which saves the current field data into the variable Food5 (or Food4 if activated from the Calories/Serving field) is the StringReplace, Food5, Food5,`,,.,all line of code which turns any accidental comma into a decimal point. It was just as well to keep the line since it totally eliminates the problem of accidentally hitting the comma key—which sits right next to the period (decimal) key. Next, we meet the first of our RegEx functions. This subroutine uses a number of RegEx functions to manipulate the data in Food5 (number of servings) until it satisfies our requirements.
RegExReplace() Function
The RegExReplace() is a simple yet powerful tool for changing matching expressions. While RegExMatch() returns the starting position of only the first match, by default RegExReplace() substitutes the new string for any and all occurrences of the match unless the number of times parameter is changed to limit substitution. This makes RegExReplace() ideal for removing unwanted characters.
The line of code NewValue := RegExReplace(Food5, "[a-zA-Z]", "") removes all of the letters (upper and lowercase) from the variable Food5 by replacing it with a blank, "", and places the result in NewValue. This does most of the work of cleaning out unwanted characters from the number variable. However, we want to exclude anything which is not a digit or decimal. A more comprehensive expression would be:
NewValue := RegExReplace(Food5, "[^\d.]", "")
If you remember from Chapter Two, the expression [\d] matches any digits found in the string. But, we want to match anything which is not a digit. When the caret ^ is placed inside a range in square brackets it means include anything that is not within that range. In this case, anything that is not a number will be removed from the string. Note that the decimal point is added to the range to prevent it from being removed from the string.
To illustrate how this expression works the following test script extracts the number from a string with other garbage mixed in:
Haystack := "a1s1?d.f0!@#$%^&*()_+g0h0j"
NewValue := RegExReplace(Haystack, "[^\d.]", "")
MsgBox %NewValue%
NewValue := RegExReplace(Haystack, "[^\d.]", "")
MsgBox %NewValue%

This snippet scans the string "a1s1?d.f0!@#$%^&*()_+g0h0j" and removes all the non-digits and non-decimal points placing the results in NewValue (see the actual results in the Figure on the left).
Quite frankly, the expression including all non-digits and non-decimal points may be all that you want when validating a number field. It will do 99% of the work. The primary downside is that it is possible to enter more than one decimal point which would again make the variable non-numeric and cause the calculation to fail. My subroutine is more complicated for a couple of reasons. The primary problems I have with stopping here are the possible multiple decimal points and that any number of zeros can be added—both at the beginning and end. I prefer to have no leading zeros unless it is a fraction—in which case I do want one leading zero before the decimal point. Plus, I don't want any trailing zeros after a decimal fraction.
However, in the future (and in the CalorieCount script posted at the ComputorEdge AutoHotkey download site), I will use the RegExReplace() line which excludes digits and decimal points from being eliminated ([^\d.]). Doing this also eliminates the need for the next line of code which uses the RegExMatch() function to find numbers and the decimal points (NewStr := RegExMatch(NewValue, "[\d.]+", NewValue)), since that is all that can possibly be returned in the new RegExReplace() line.
Note: I find different, often better, ways to do things while writing about AutoHotkey. For example, after writing many more of the RegEx AutoHotkey chapters, I might be able use look-ahead and look-behind assertions (Chapter Twelve) in this numeric validation to write a more elegant RegEx which does the required job, but I haven't had time to get back to it. This is normal when learning new script writing techniques. There are so many different ways to do anything in AutoHotkey—especially RegEx—it's impossible to always know the best way to proceed. Since I'm only learning the ins and outs of RegEx, I expect that I may change direction many times. It's all part of both the learning and programming process.
Forcing a Number Type from a String
One of the characteristics of AutoHotkey is that variables are stored as strings—even if they are intended to be numbers. It's not until they are used as a number that that problems in formatting will appear. A number type can be forced by using the string in a number function such as Round(). But an easier method which will not affect the value (i.e. rounding) is to use the string in a calculation by adding zero to itself:
NewValue += 0
The =+ operator will increment the variable by the amount to the right of the operator (0). This will return a number type variable in the default number format (usually 0.00000). If the string is not a number (i.e. two or more decimal points), it will return the value which appears before the first decimal point.
The problem comes up when the entire format is added with all the decimal places on the right of the string. If you're using a subroutine which validates as each character is typed (as is the case here), it causes problems with data entry. (One solution might be to run the validation routine only when the edit field is exited.) While this calculation technique resolves the leading zero problem, I added some conditional RegExMatch() functions to deal with the trailing zeros.
But first, the SetFormat command (SetFormat, float, 5.2) is used to reduce the number of decimal places from the default six to two. I don't need more that two decimal places, plus anymore than two would greatly complicate my conditionals for removing trailing zeros. (The reason I need to remove trailing zeros is because at the end of the validation routine, the cursor is set to the end of the field. If I don't first remove the unneeded zeros at the end, then I will be forced to reposition the cursor by hand to the appropriate position to before continuing to enter a decimal fraction.)
Matching the End of a String
To remove the trailing zeros, the end of the string must be matched. The trailing zeros should only be removed if they appear after a decimal point. The first case is two trailing zeros:
NewStr := RegExMatch(NewValue, "\.00$")
If NewStr ; remove double zeros after decimal
NewValue := SubStr(NewValue, 1 , NewStr)
If NewStr ; remove double zeros after decimal
NewValue := SubStr(NewValue, 1 , NewStr)
This form of RegExMatch() returns the starting position of the match only if it finds ".00" at the end of the string—otherwise the value 0 or false. The \., which must have the preceding backslash, represents the decimal point. (The backslash "\" escapes the period (.) so that it will not perform its usual wildcard function, but merely act as a decimal point.) The $ at the end of the expression is the end of line anchor which requires the match to occur only at the end of the string. (This is the opposite of the beginning anchor "^" mentioned earlier which matches only at the beginning of a string.) If the match is found (NewValue does not equal 0), then the SubStr() function is used to truncate the zeros by ending the string at the decimal point (NewStr)—ready for entry of the tenths fraction.
The next check is for a single 0 at the end of the two place decimal:
NewStr := RegExMatch(NewValue, "\..0$") ; detect single zero at end
If NewStr ; remove single zero
NewValue := SubStr(NewValue, 1 , NewStr+1)
If NewStr ; remove single zero
NewValue := SubStr(NewValue, 1 , NewStr+1)
The primary difference in this RegEx from the previous one is that the period (.) is used as a wildcard to represent any character. The RegEx first looks for the decimal point (\. the period escaped with the backslash). If found it looks for any single character (the period (.) as a wildcard), then a zero (0), all at the end of ($) of the string. If found, the new string is set to a length one place after the decimal point (NewStr+1).
The remainder of the label (subroutine) updates the Number of Servings in the Food5 edit files (GuiControl, ,Food5, %newvalue%), sets the cursor to the end of the field (SendInput, {End}), calculates the total number of calories (TotalCalVal := Round(Food4 * Food5)), and updates the text displaying Calories for the food item (GuiControl, , Food6, %TotalCalVal%).
The primary issue with this approach to validating Number of Servings is that it is impossible to enter a zero directly after the decimal point for fractions containing only hundredths. You must first enter the number as a tenth, then move the cursor to just after the decimal point and enter the zero. This is a minor issue in this application since the need to enter hundredths of a serving when counting calories would be rare.
* * *
A Learning Experience with an Improved Solution
Early in my wanderings through Regular Expressions (RegEx) I used the AutoHotkey RegEx functions (RegExMatch() and RegExReplace()) to control the formatting of the number of servings field in the CalorieCount.ahk script. As I worked with the expressions and tried to clean up the problems, the snippet of code became more and more involved. (Sometimes the light comes on slowly. The more I work with RegEx, the more insight I gain.) I finally came across a sample RegEx expression for validating numbers. It was simple and allowed me to eliminate a number of lines of code. An explanation of the new code and how it eliminated the need for the old lines may help you get a better understanding of how to use RegEx in AutoHotkey. It did me.
The following is the AutoHotkey code from the old method used to validate the Number Servings field:
TotalCalCalc: ;Calculate total calories
Gui, Submit, NoHide
StringReplace, Food5, Food5,`,,.,all ; turn commas into decimals
NewValue := RegExReplace(Food5, "[a-zA-Z]", "") ; remove letters
NewStr := RegExMatch(NewValue, "[\d.]+", NewValue) ; match all numbers and decimals
SetFormat, float, 5.2 ; set number format to two decimal places
NewValue += 0 ; forces the variable to be a number
NewStr := RegExMatch(NewValue, "\.00$") ; detect double zeros after decimal
If NewStr ; remove double zeros after decimal
NewValue := SubStr(NewValue, 1 , NewStr)
NewStr := RegExMatch(NewValue, "\..0$") ; detect single zero at end
If NewStr ; remove single zero
NewValue := SubStr(NewValue, 1 , NewStr+1)
GuiControl, ,Food5, %newvalue% ; update value of Number Servings
SendInput, {End} ; place cursor at the end of the field
TotalCalVal := Round(Food4 * Food5)
GuiControl, ,Food6, %TotalCalVal%
Return
Gui, Submit, NoHide
StringReplace, Food5, Food5,`,,.,all ; turn commas into decimals
NewValue := RegExReplace(Food5, "[a-zA-Z]", "") ; remove letters
NewStr := RegExMatch(NewValue, "[\d.]+", NewValue) ; match all numbers and decimals
SetFormat, float, 5.2 ; set number format to two decimal places
NewValue += 0 ; forces the variable to be a number
NewStr := RegExMatch(NewValue, "\.00$") ; detect double zeros after decimal
If NewStr ; remove double zeros after decimal
NewValue := SubStr(NewValue, 1 , NewStr)
NewStr := RegExMatch(NewValue, "\..0$") ; detect single zero at end
If NewStr ; remove single zero
NewValue := SubStr(NewValue, 1 , NewStr+1)
GuiControl, ,Food5, %newvalue% ; update value of Number Servings
SendInput, {End} ; place cursor at the end of the field
TotalCalVal := Round(Food4 * Food5)
GuiControl, ,Food6, %TotalCalVal%
Return
This subroutine uses both the RegExMatch() and RegExReplace() functions. There are a number of conditionals included to clean up the data. Plus, a mathematical operation was used to convert the variable to a number—if only temporarily.
The new snippet of AutoHotkey code is as follows:
TotalCalCalc: ;Calculate total calories
Gui, Submit, NoHide
StringReplace, Food5, Food5,`,,.,all ;turn commas into decimals
NewStr := RegExMatch(Food5, "[0-9]+\.?[\d]?[\d]?" , NewValue) ;extract number
If NewStr = 0
NewValue := "0."
NewStr := RegExMatch(NewValue, "^0\d") ;detect single zero at beginning
If NewStr ;remove single zero
NewValue := SubStr(NewValue, 2)
GuiControl, ,Food5, %newvalue% ;update value of Number Servings
SendInput, {End} ;place cursor at the end of the field
TotalCalVal := Round(Food4 * Food5)
GuiControl, ,Food6, %TotalCalVal%
Return
Gui, Submit, NoHide
StringReplace, Food5, Food5,`,,.,all ;turn commas into decimals
NewStr := RegExMatch(Food5, "[0-9]+\.?[\d]?[\d]?" , NewValue) ;extract number
If NewStr = 0
NewValue := "0."
NewStr := RegExMatch(NewValue, "^0\d") ;detect single zero at beginning
If NewStr ;remove single zero
NewValue := SubStr(NewValue, 2)
GuiControl, ,Food5, %newvalue% ;update value of Number Servings
SendInput, {End} ;place cursor at the end of the field
TotalCalVal := Round(Food4 * Food5)
GuiControl, ,Food6, %TotalCalVal%
Return
This new subroutine eliminates the need to use the RegExReplace() function at all and only uses RegExMatch() twice. There are a number of code lines eliminated or replaced. The math operation is no longer used and overall the RegEx does a better job of delivering a satisfactory result.
The New RegEx
Remember that the goal was to prevent the entering of non-numeric digits (in particular the comma which sits right next to the decimal point on the main keyboard) into the Number of Servings editing field. If the variable does not evaluate as a number, then the total Calories calculation will return 0. I was using a number of tricks which included removing all non-digits and non-decimal points with:
NewValue := RegExReplace(Food5, "[a-zA-Z]", "")
This function strips all letters (lowercase and uppercase) from the variable Food5. As it turns out, I never really needed this line. (Yes, I'm still learning.)
In the next function:
NewStr := RegExMatch(NewValue, "[\d.]+", NewValue)
the first set of numbers encountered (plus any decimal) is extracted from the remaining string. The key word is extracted. I should have been thinking in terms of extracting the desired number from the string when using the RegExMatch() function rather than merely matching, but with my lack of experience in AutoHotkey RegEx I was caught up in doing everything one step at a time. When I saw the new expression ([0-9]+\.?[\d]?[\d]?), a light turned on:
NewStr := RegExMatch(Food5, "[0-9]+\.?[\d]?[\d]?" , newvalue)
The RegEx in this one line of code does almost all the work needed.
If we breakdown this new expression and understand that any matched string will be extracted from the target string and placed in the variable NewValue, we see why it is no longer necessary to use the RegExReplace() function to remove any extra letters or characters. They are merely left behind by the extraction.
The first part of the RegEx ([0-9]+) is a range that includes and digits between 0 and 9. When a number is encountered, the match begins. In this part of the expression the plus sign (+) is added to the range telling RegEx to continue matching as long as the next character is a digit. If not, stop. While this is very similar to my original expression ([\d.]+) which matched digits with \d and any decimal point (.), the remaining portions of the expression make it much more elegant for finding a number with one decimal point and up to two decimal places. (Remember that \d and [0-9] are interchangeable per the AutoHotkey RegEx Quick Reference. In fact, the new expression could just as easily be stated as \d+\.?\d?\d? without any square brackets.)
Whenever a question mark (?) follows a letter or class it designates an optional match. If, after the RegEx runs out of the first set of numbers, the next character happens to be a decimal point (\. the escaped dot), then it will be included in the match. But that's optional as expressed by the following question mark (?). If there is no decimal point following the numeric matches, then the matching stops and returns the initial digits as a group.
If the decimal point is matched directly after the first set of numbers, it is included in the match and RegEx moves on and checks the next character. If that next character happens to be a digit (\d?), then that digit is included. But that's optional as shown by the question mark. The same is true for the second digit as shown by the repeated expression (\d?). If you wanted to include more than two decimal places, then the same expression could be used the appropriate number of times.
Note: Another way to express 0 to 2 decimal places is with the {min,max} expression. For example, \d{0,2} has the same effect as \d?\d? in the same example. The 0 as minimum makes inclusion in the match optional. As can be seen, there are often multiple ways to express the same thing.
This new expression does almost everything that we want to validate a number up to two decimal places. It extracts any number and places it in the variable NewValue. There is no need to strip any letters or characters because they will not be extracted or included in NewValue. You could stop here and the validation of the Number Servings field would work fine, but for me there are a couple of issues to address.
No Number Found
If no number is found the RegExMatch() function will return 0 and the NewValue variable will be blank. This could happen if you highlighted the editing field and entered a decimal point to add a value of less than one. There is no provision in the RegEx to start a match with a decimal point—only digits. This could create an awkward situation where decimals could not be added unless a 0 is first inserted. Therefore the following trap is added to facilitate adding decimals and dealing with non-matches (no number found):
If NewStr = 0
NewValue := "0."
NewValue := "0."
If no match is found (as would be the case for a sole decimal point, a blank field, or a letter), the function returns 0 to NewStr, then NewValue is set equal to 0. ready for the addition of decimal fractions. Whenever a decimal point is entered into a blank field, the leading zero is added making it a valid match.
Leading Zeros in the Match
Purely for cosmetic reasons, I don't want a number starting with the 0 digit unless it is a decimal fraction. But in its current form the RegEx allows any number of leading zeros. For example, 0087.34 would be an acceptable match. While it would have no impact on operation of the script, it looks bad.
I could return to the code I used originally which converted the variable to a number:
SetFormat, float, 5.2 ; set number format to two decimal places
NewValue += 0 ; forces the variable to be a number
NewValue += 0 ; forces the variable to be a number
but then I would be dealing with unnecessary decimal places when none are needed (as shown in the original code). I decided to use RegExMatch() to look for leading zeros, then eliminate them:
NewStr := RegExMatch(NewValue, "^0\d") ;detect single zero at beginning
If NewStr ;remove single zero
NewValue := SubStr(NewValue, 2)
If NewStr ;remove single zero
NewValue := SubStr(NewValue, 2)
The bit of code looks for a match of 0 plus a digit at the beginning of the NewValue string. By looking for a digit after the 0, zero with a decimal (0.) is eliminated as a match. If a match is found, NewValue is stripped of its leading zero by returning it to itself (SubStr(NewValue, 2)) starting at the second character.
Originally, I obsessed over removing trailing zeros after the decimal point. This new expression has the same problem of leaving the zeros if they are added. Plus, it is possible to enter a decimal point with no fraction which looks odd. I don't know if there is a way to deal with this other than using the original code, but I'm going to leave it out for now. It works pretty well the way it is. I might later do reformatting when a food item is added to the list to eliminate hanging decimals and trailing zeros in the decimal places. For now the improved functionality of the expression and the new insights are enough for me.
Note: A second trailing zero is fairly easy to prevent by changing the last portion of the expression from [\d]? to [1-9]? which eliminates 0 from the range, thus preventing a 0 in the second decimal place ([0-9]+\.?[\d]?[1-9]?). However, this will not work for the first decimal place since fractions of a tenth would require the first 0 (i.e. 0.07, 0.08,…). This last variation is now included in the CalorieCount.ahk script available at ComputorEdge AutoHotkey download site.
Chapter Five: Eliminating Double Words with RegEx
“How to Use AutoHotkey RegEx to Eliminate Duplicate Words--RegExReplace()”
Digging deeper into AutoHotkey RegEx with an expression that will find and remove double words in any text, anywhere.
Finding Double Words with RegEx in AutoHotkey
Regular Expressions often are neglected in programming because it takes a little time to understand how they work. However, when used properly there is power in RegEx which can easily replace many lines of standard AutoHotkey code. The problem is writing the correct expression.
The task in this chapter is to write an AutoHotkey RegEx expression which locates duplicate words in a highlighted section of text. I started with a sample taken from another Web page and placed it in the RegEx Tester discussed in Chapter One (Figure 1). I used the RegExReplace tab of the tester so that I could immediately see the results of any changes I made to the expression.

Figure 1. The RegEx Tester is used to evaluate an expression for eliminating duplicate words in selected text.
I entered sample text into the top edit field, "Text to be searched"; the copied expression in the second box; next, the "Replacement Text" which is a subpattern ($1) of the first expression match (inside the parentheses); then the resulting text appears in the bottom window. None of the expressions I found on the Web worked as well as the RegEx shown:
i)\b([\w\S]+)\s+\1\b
which evolved as I tested various possibilities. There are a number of learning points in this RegEx worth investigating.
While the sample text doesn't make any sense, its purpose—checking for various types of double words—uncovered a number of problems in the original expressions. By starting at the beginning of the RegEx and examining each piece of it, techniques not previously discussed are highlighted in a practical way.
RegEx Options (Ignore Case)
There are a series of options which can be used to modify an entire AutoHotkey RegEx by placing them at the beginning of the expression followed by a close parenthesis (see the AutoHotkey RegEx Quick Reference page). The code i) located at the beginning of our expression tells RegEx to ignore differences in case. Previously, the capital letter which appears in the sample text at the beginning of a sentence (The the) would not match the same lowercase letter at the beginning of the next word, but adding the i) option completed the match. The original expression did not account for double words at the beginning of a sentence. By making the entire expression case insensitive the problem is eliminated.
Tip: It is well worth the time to investigate the various RegEx options—expressions with an option code and a close parenthesis i) at the beginning of the expression. For example, P) (position) returns the position and length of expressions to variables when used with the RegExMatch() function. This is particularly useful when extracting multiple items in the haystack inside a Loop. Even better, O) (MatchObject) saves the object properties and returns the position, length, value and a few other properties in Object Oriented Programming (OOP) format. (If you use some of these RegEx options, the result will not necessarily be displayed in Ryan's RegEx Tester. You will need to write your own simple AutoHotkey test script such as:
Haystack := "Abby has always been absent from the abbey."
FoundPos := RegExMatch(Haystack, "O)(absent)", newvariable)
MsgBox % FoundPos " " newvariable.Value[0] " " newvariable.Pos[0] " " newvariable.Len[0]
FoundPos := RegExMatch(Haystack, "O)(absent)", newvariable)
MsgBox % FoundPos " " newvariable.Value[0] " " newvariable.Pos[0] " " newvariable.Len[0]
While Ryan's RegEx Tester is great, it doesn't do everything.)
Matching Words Only
It was found in some of the expressions that when the first word ended with the same letter which started the second word a match was found. This produced results in the test such as "thoughthough" and "don'take" rather than recognizing that there was no match. The code \b is similar to the line anchors ^ and $ in that it doesn't take up any characters. It is used as a word boundary.
For a match to occur the boundary (either beginning or end) must not be a letter (or digit) character, but can be any punctuation or space. This isolates the match as a word and prevents matching within words. The example given online is "\bcat\b doesn't match catfish, but it matches cat regardless of what punctuation and whitespace surrounds it." In our case, using the boundary marks \b prevents matching between ending and beginning letters in the two words. The first \b eliminates the problem noted above. The last \b is needed to prevent matches such as "do doh" which would yield "doh" as the replacement.
Matching Contractions
Another problem with some of the expressions I found online for identifying duplicate words was that they missed contractions. For example, "you're you're" would be missed because the apostrophe was assumed to be the start of a new word with "re" and the following "you" not matching. This was fixed by adding a class of characters (a range using the square brackets []) which includes any letters or digits \w or any non-space \S in the form [\w\S]+. This expression tells RegEx to match anything that is either a character (upper or lowercase), digit (0-9), or anything which is not a space. The \S with a capital S means "not a space", while \s with a lowercase s means any space. The plus sign + tells RegEx to continue matching characters until it encounters a space (which would includes end of line characters such as `r for carriage return and `n for newline or linefeed). Now the combination "you're you're" will match eliminating one of the words.
Eliminating Extra Spaces
Some of the samples only used one space \s as a separator between the words. If extra spaces are inadvertently inserted between the duplicate words, then there will be no match. By adding the repeat plus + sign to the \s (\s+), the matching continues as long as spaces are encountered. Any other intervening character stops the matching process. This expression will now find duplicate words with any number of intervening spaces and ignore them in the final result.
Using a Backreference to Make the Match
One of the most power features in RegEx is the ability to match previously matched sub-expressions. This are called a backreference and is called by enclosing the desired portion of the expression inside a set of parentheses ()—in this case ([\w\S]+) which matches the first word. By adding \1 (backslash and the number one) near the end of the expression, RegEx is told to use the results of the first backreference for the next match. (This use of the backreference \1 is not found in the AutoHotkey RegEx Quick Reference Guide, but is in many other more extensive Regular Expression references.) Similar to using $1 for a replacement backreference in RegExReplace(), the \1 uses the match found in the first set of parentheses. Other backreferences would be \2 for the second subpattern, \3 for the third, through \9 for the ninth. (In most programming languages a RegEx backreference can go up to \99 (99 sets of parentheses), although it is difficult for me to see a situation where one would need so many. Since I haven't tested it, I can only assume that RegEx in AutoHotkey has the same 99 backreference limitation. For backreference replacements above $9 in RegExReplace() use curly brackets, i.e. ${10}, ${10}, etc.)
By using the \1 all double words are matched. If you wanted to match triple words, then add \s+\1 to the expression like so:
i)\b([\w\S]+)\s+\1\s+\1\b
If you want to match repeated two word combinations such as "you are you are", then add a second word expression and a second backreference \2:
i)\b([\w\S]+)\s+([\w\S]+)\s+\1\s+\2\b
which would yield the result "you are" if the replacement expression "$1 $2" is used.
Writing a RegEx to Mark Double Words
While this expression for finding double words seems to work pretty well, you may not want to use if for direct replacement in a long section of text. There may be times when either you don't want a double word removed ("What is it that you do do?") or there may be an inappropriate match I haven't seen yet. It might be better to mark the double matches for later review with a built in search tool. This can be done by adding special symbols to the text at the double word location while returning the entire expression to the text using $0 which replaces the match with the entire original match (including the backreference):
NewValue := RegExReplace(Haystack, "i)\b([\w\S]+)\s+\1\b", "$0+++")
This example of the AutoHotkey RegExReplace() function adds triple plus signs (+++) at each location where a double word is found. The matches can be reviewed by finding "+++" using the built-in search feature found in virtually all editors and browsers.
If you want to eliminate the double words on one pass, then:
NewValue := RegExReplace(Haystack, "i)\b([\w\S]+)\s+\1\b", "$1")
The two repeated words are replaced with the first backreference ($1) which is the single word.
Each of these example functions is almost an entire AutoHotkey script. All that needs to be added is the value of Haystack (the input text) and a way to retrieve or display NewValue (the changed text). The first will mark the double words, while the second will eliminate one of the double words.
Chaper Six: Fixing Contractions with RegEx
“RegEx can fix multiple errors in contractions such as isn't and won't--RegExReplace()”
Another practical example of a Regular Expression in AutoHotkey with word contractions.
A Regular Expression (RegEx) Trick with Contractions
Since the apostrophe key (') and the semicolon key (;) site next to each other on the keyboard, it is common to accidentally enter the semicolon when typing a contraction rather than the apostrophe (you;re). You can add these errors to script as is done in the AutoHotkey AutoCorrect script found in the Digging Deeper into AutoHotkey book, but that means entering a line of code for every possible word and variation. With RegEx it is possible to find the problem contractions without knowing the specific words.
Similar to last chapter's RegEx which finds double words in selected text, this RegEx uses backreferences to replace the recalcitrant contraction. Again Robert Ryan's RegEx Tester is used to evaluate the expression (see Figure 1). This expression identifies contractions with a semicolon (;), comma (,), or double quote mark (") rather than the desired single quote (apostrophe ').

Figure 1. The RegExReplace tab of RegEx Tester is used to evaluate an expression for correcting typos in contractions.
The RegEx which identifies contractions with the wrong punctuation is:
i)\b(\w+)[;,"](\w+)\b
In this case it includes two backreferences, but unlike the last chapter, a backreference is not used in the RegEx code. However, it is important to the replacement expression ($1'$2).
The expression \b (as discussed in Chapter Five) encloses the entire expression and is used to bind any matches as individual words (surrounded by spaces or punctuation).
There are two sets of parentheses in the example. These are needed only to identify the two backreferences ($1 and $2). The first expression (\w+) matches the first part of the contraction which can contain any number of sequential letters or digits.
Wait! I just noticed that using the \w expression accepts numbers embedded in the supposed contraction. While it is unusual to find numbers inside words, it can happen all the time in computerese. Since I don't want to match any words which happen to include embedded digits, the \w is changed to the range [a-z] which will only match letters:
i)\b([a-z]+)[;,"]([a-z]+)\b
The option i) discussed in the last chapter causes the expression to ignore the case of the letters, therefore it works for both the capital and lowercase alphabet. Otherwise the new expression would need to include [a-zA-Z].
The center range [;,"] includes a few of the possible punctuation marks which might be inadvertently entered in the contraction. The match can be any one of these characters. I left out the period (.) because there are too many URLs which contain periods. Those periods would be switched to apostrophes.
The expression inside the second set of parentheses (now [a-z]+) matches the second backreference and uses the same expression as the first backreference. If I wanted to limit the number of characters in the expression—most contractions only have one or two characters at the end—I can add the {min,max} parameter like so:
i)\b([a-z]+)[;,"]([a-z]{1,2})\b
This RegEx makes a match only when the second part of the contraction has one or two letters. On the downside, it would miss any "o'clock" with the wrong punctuation.
If you wanted to use the expression as a search and replace parameter, then the RegExReplace() function would be:
NewValue := RegExReplace(Haystack, "i)\b([a-z]+)[;,""]([a-z]{1,2})\b", "$1'$2")
This RegEx technique fixes typos in contractions. While there may not be great demand for this particular function, there a other times when unknown character combinations need to be quickly parsed and recombined forming a new string such as modifying multiple filenames. (Note the double double quote "" needed to escape the double quote character within the AutoHotkey function, but not in
Ryan's RegEx Tester.)
Ryan's RegEx Tester.)
Chapter Seven:A Simple Beginner's Trick for Swapping Letters and Words
“An AutoHotkey Technique for Swapping the Order of Words--RegExReplace()”
Jack shows some easy AutoHotkey techniques for swapping errant letters or words, then step-by-step builds a Regular Expression (RegEx) for doing the same thing and more—with only one line of code.
This chapter starts out with some beginning AutoHotkey tips using basic commands (non-RegEx) for correcting minor typos by swapping letters or words while editing text in any Windows program or Web browser. Then, a simple Regular Expression is introduced to swap two words. Step-by-step that expression is modified to handle more and more complex situations. Eventually, an expression which swaps the first and last words in almost any highlighted text is offered. This second part of the chapter is a good example of the thought process involved in developing those complex Regular Expressions from a simple beginning.
The Beginner's AutoHotkey Tip for Swapping Letters and Words
A while back I introduced a simple AutoHotkey script for fixing a common typo—Chapter Five in the Digging Deeper into AutoHotkey book. I added it to my basic running AutoHotkey script. Whenever I notice that I've reversed two letters (tset for test) I can highlight the two letters and press the ALT+R (!r) hotkey combination and the two characters swap position within the word. I use this hotkeys from time to time even though it is relatively easy to either drag one letter to the correct position (in any program that supports dragging) or delete one letter and re-enter it in the proper place. Sometimes it's just seems quicker.
However, I noticed that if I accidentally highlighted more than two characters or needed to move a letter more than one space, then the routine would delete the extra characters. There is a relatively simple fix for this letter swap:
!R::
SendInput, ^c
Sleep, 100
Clipboard := SubStr(Clipboard,2) . SubStr(Clipboard,1,1)
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
Clipboard := SubStr(Clipboard,2) . SubStr(Clipboard,1,1)
SendInput, ^V
Return
This script is almost identical to the original code. The assigned hotkey combination is ALT+R as shown by the !R assignment in the first line of code. The selected characters are sent to the Windows Clipboard (SendInput, ^c). A pause is added to the running script to allow enough time for the characters to appear in the Clipboard (Sleep, 100). Then, the Clipboard text is parsed and reshuffled (Clipboard := SubStr(Clipboard,2) . SubStr(Clipboard,1,1)). This SubStr() function is where the current routine differs from the original.
In the old snippet I used:
Clipboard := SubStr(Clipboard,2,1) . SubStr(Clipboard,1,1)
for parsing and swapping the characters. The problem was that I limited the second part of the swap starting with the second character to only one character (SubStr(Clipboard,2,1)), thus eliminating any additional letters. By eliminating the second number in the function, the string is expanded to the entire remainder of the string, thus moving the first character to the end of the string. The new rearranged text is sent back to replace the highlighted characters (SendInput, ^V). Admittedly, this only moves the first character to the end of the selected string and another hotkey would be required to move a letter to the front of the line, but this seems to suffice for now. Generally, CTRL+Z can be used to Undo any mistakes in most Windows programs and apps.
But what if we want to swap two words in any text?
Swapping Two Words with AutoHotkey
When I reread my writing, it's not unusual for me to notice that I occasionally reversed the order of two words. (I know that it doesn't seem possible, but it does happen—even though I know the words were properly situated in my head.) If I'm working on the Web, it's easy enough to highlight one of the words and drag it to the proper location. (It's not so easy in Notepad which does not allow dragging.) But wouldn't it be nice to highlight the two words and hit a hotkey combination to swap them. With a relatively simple adjustment to the first script the feature is added to a Windows computer:
!W::
SendInput, ^c
Sleep, 100
Position := InStr(Clipboard, " ")
Clipboard := SubStr(Clipboard,Position+1) . " " . SubStr(Clipboard,1,Position-1)
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
Position := InStr(Clipboard, " ")
Clipboard := SubStr(Clipboard,Position+1) . " " . SubStr(Clipboard,1,Position-1)
SendInput, ^V
Return
This time the hotkey combination has been changed to ALT+W (!W) for swapping words. The script looks almost identical except the InStr() function has been added to locate the position of the space between the two words in the Clipboard (Position := InStr(Clipboard, " ")). This is needed to properly parse, then reverse the order of the two words with the SubStr() function.
The Position of the space is used in with the SubStr() function to clip the words and recombine them with a space between them (SubStr(Clipboard,Position+1) . " " . SubStr(Clipboard,1,Position-1)). This works well as long as there is one space between the two words and the same punctuation at the end of each word. Otherwise, we get into more complicated parsing while adding more lines of code. The same happens if we decide that we want to swap words with a conjunction between them (e.g. "and", "or").
Swapping "Bows and Buttons"
Everyone knows that the proper order for these words is "buttons and bows", not "bows and buttons." But if you happen to type them in the wrong order it's tedious to fix them, even if you can drag each word around with a mouse. At a minimum, you must drag one word to the other side, then drag the other back to the new location. Wouldn't it be easier if you could highlight the entire three word combination and hit a hotkey combination to do the entire job?
This word rearranging can be done with the usual AutoHotkey commands, but it gets a little more complicated:
!A::
SendInput, ^c
Sleep, 100
StringGetPos, Position1, Clipboard, %A_Space%
StringGetPos, Position2, Clipboard, %A_Space% , R
Clipboard := SubStr(Clipboard,Position2+2) . SubStr(Clipboard,Position1+1,Position2-Position1+1)
. SubStr(Clipboard,1,Position1) ; continued from previous line
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
StringGetPos, Position1, Clipboard, %A_Space%
StringGetPos, Position2, Clipboard, %A_Space% , R
Clipboard := SubStr(Clipboard,Position2+2) . SubStr(Clipboard,Position1+1,Position2-Position1+1)
. SubStr(Clipboard,1,Position1) ; continued from previous line
SendInput, ^V
Return
Notice that I have switched from the InStr() function to the StringGetPos command for this AutoHotkey snippet. I did this mostly to show the alternative command for locating the position of a character within a string. The two work in an almost identical manner except the first position is 0 for StringGetPos whereas it is 1 for InStr() because 0 would be false (no match found) in the function.
There are now two lines of code for finding the location of the two spaces (Position1 and Position2). The first line finds the first space while the second finds the first space from the right (see the R in StringGetPos, Position2, Clipboard, %A_Space% , R).
The Clipboard := statement gets much longer (I had to fold it with AutoHotkey line continuation for the Web site) and a little more complicated to figure out. The first SubStr() returns the last word which starts at Position2+2. (Remember that the first position is 0 with the StringGetPos command, so then we must add 2 to the position of the space rather than one for the SubStr() function.) The center section of the text remains the same, but must be extracted with a more complex expression (SubStr(Clipboard, Position1+1, Position2-Position1+1)). The last word is a clipping of the beginning of the Clipboard text (SubStr(Clipboard,1,Position1)). This works pretty well. In fact it will swap two words anywhere in a document as long as they are the first and last word in highlighted selected text. But if there is a punctuation mark immediately following the end of the first word, it will also be moved in the swap. Aarrgghh!
As you can see, the more we do with the AutoHotkey commands and functions, the more complicated it becomes. What if we want to deal with the problem of swapping words with punctuation such as a comma or semicolon following the first word? We most likely won't want that character moving with the word. It's time to look at RegEx for using less code while producing more powerful swaps.
Swapping Words with RegEx in AutoHotkey
If you're only doing the simple character and word swaps shown in the beginning of this column, then it's probably better to avoid Regular Expressions (RegEx) and use the quicker AutoHotkey commands and functions. However, a RegEx can deal with more complex situations without making the snippets of code too complicated. But first let's look at how a RegEx can do a word swap with one less line of code:
!W::
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"(\w+)\s(\w+)","$2 $1")
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"(\w+)\s(\w+)","$2 $1")
SendInput, ^V
Return
When using the RegExReplace() function, we no longer a need to locate the position of the space between the two words (as long as it exists). It is simply a matter of identifying the first word (\w+), the space in between \s, and the last word (\w+). The expression \w means match any letter or digit—the same as the range [a-zA-Z0-9]. Adding the plus sign + tells RegEx to continue matching characters as long as it is of the same type (letter or digit). To match a space the expression is \s. The first word match continues until it reaches a non-letter, non-digit, or space. After the space \s, the same expression is used to match the second word (\w+).
The parentheses around the two word expressions create backreferences (or subpatterns) for use in the replacement. When doing the replacement with RegExReplace(), the value in the first set of parentheses is indicated by $1 while the second is $2. With the backreferences reversed, $2 $1 (with a space between the two) in the above function, the words are swapped and inserted into the application.
This is fine for the simple swapping of words only separated by a space, but what if we want to swap "bows and buttons" in a text string?
Swapping Words with a Conjunction
Suppose we want a RegEx which will swap two words separated by a conjunction—for example "bows and buttons" to "buttons and bows"—the proper order for these particular words? A single hotkey combination would certainly be a more useful technique than the steps involved in doing it by hand. The expression must be changed to recognize the conjunction:
!W::
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"(\w+)\s(\w+)\s(\w+)","$3 $2 $1")
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"(\w+)\s(\w+)\s(\w+)","$3 $2 $1")
SendInput, ^V
Return
A third backreference \s(\w+)\s with a space \s on either side has been inserted in place of the original \s to recognize the word in the middle. However, since backreferences are by default numbered in the order they appear from left to right, the new insertion is represented by $2 in the replacement string and $3 is now assigned to the last matched word. To reverse the first and last word the replacement expression is $3 $2 $1 with a space between each.
But what if we wanted to swap words with both a conjunction and punctuation such as the "bows" and "buttons" in "ribbons, bows, and buttons" phrase? The comma after the word "bow" (bow,) would cause a problem and prevent the swap since it would prevent a match. What's needed is an optional punctuation match which only appears when needed.
Optional Punctuation in a RegEx
Since sometimes there is punctuation after the word just before the conjunction (usually a comma or semicolon), the expression needs to recognize and match these situations. The expression \S (with an uppercase S) matches any non-space character (which includes punctuation). Placing this just after the first word expression and adding the question mark \S? makes it an optional match following the first word:
!W::
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"(\w+)(\S?)\s(\w+)\s(\w+)","$4$2 $3 $1")
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"(\w+)(\S?)\s(\w+)\s(\w+)","$4$2 $3 $1")
SendInput, ^V
Return
Enclosing the new subexpression in parentheses turns it into another backreference. This time the renumbering of backreferences from beginning to end makes it $2 for the new replacement string. When there is a comma or semicolon, it will appear in $2. Otherwise, it is blank. Therefore the replacement expression $4$2 $3 $1 will leave the punctuation in place whenever there is a swap.
This works fine for swapping the last two words in a series, but what if we want to swap two words which are farther apart?
Swapping Any Two Words with RegEx
So far we have a RegEx which will reverse the position of any two words in a series separated by a conjunction—with or without punctuation. But now we want to also swap two words which are farther apart. For example, the "ribbons" and "buttons" in "ribbons, bows, and buttons." If we highlight the entire text and use the hotkey combination, the result continues to switch the "bows" and "buttons" because it is the first match found that fits the expression. The expression needs to change so that it will match any combination of words and characters between the first and last word:
!W::
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"(\w+)(\S?)\s(.*)\s(\w+)","$4$2 $3 $1")
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"(\w+)(\S?)\s(.*)\s(\w+)","$4$2 $3 $1")
SendInput, ^V
Return
The center expression is changed from a word (\w+) to a wildcard (.*) which matches anything and everything between the first and last word—as long as it's in the same paragraph. The dot . means match any character and the asterisk * tells RegEx to continue matching until reaching the end of the string. The last space and word \s(\w+) continues to match at the end of the selected text. Now "ribbons, bows, and buttons" becomes "buttons, bows, and ribbons" swapping the first and last words—regardless of how many words, digits, or characters appear between the two.
The Problem of Swapping Contractions
This last RegEx works pretty well except when one of the words is a contraction. The apostrophe ' cuts off the match making the swap only include the letters following that apostrophe. The RegEx needs adjustment to allow for contractions. This is done by adding a range to the first and last word expressions which include the apostrophe ([\w']+\w):
!W::
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"([\w']+\w)(\S?)\s(.*)\s([\w']+\w)","$4$2 $3 $1")
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"([\w']+\w)(\S?)\s(.*)\s([\w']+\w)","$4$2 $3 $1")
SendInput, ^V
Return
A range is enclosed with square brackets [] with RegEx matching any character within the range. In this case [\w'] it is either any letter or digit \w, or the apostrophe ' punctuation mark. The plus sign + is added outside the square brackets to continue the matching as long as one of the characters within the range is encountered. This means that it is possible for the word to have multiple apostrophes—which is unlikely to cause a problem.
The last \w is added after the plus sign to ensure that the word ends with a letter or digit—not a apostrophe. This will prevent confusion with a trailing single quote.
This RegEx seems to work in most situations but it will not work when all you want to do is swap two words with only a space in between—our original beginner's problem and our original, simple RegEx. It would be a shame to use a separate hotkey combination to do such an easy word swap.
Adding Alternatives to RegEx Matches
The last RegEx is excellent for swapping the two words at the beginning and end of selected text—including contractions—but it won't work for two words with only a space between them. To prevent the need for another hotkey combination an alternative match is added to the expression:
!W::
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"([\w']+\w)(\S?)(\s.*\s|\s+)([\w']+\w)","$4$2$3$1")
SendInput, ^V
Return
SendInput, ^c
Sleep, 100
Clipboard := RegExReplace(Clipboard,"([\w']+\w)(\S?)(\s.*\s|\s+)([\w']+\w)","$4$2$3$1")
SendInput, ^V
Return
As it turns out, the fix is relatively simple. Alternative matches can be added to a subexpression by placing the pipe | (vertical line) between the options (\s.*\s|\s+). In this case, the RegEx can match either \s.*\s (anything surrounded by two spaces) or \s+ (one or more spaces in a row), but not both. This quickly adds the option to switch two words only separated by spaces eliminating the need for a second RegExReplace() function line.
Notice that I needed to move the two spaces surrounding the wildcard .* inside the backreference \s.*\s. This was necessary to prevent the expression from looking for multiple spaces when the space-only match was made. In addition, the plus sign was added to the single space option just in case there is more than one space between the two words. To compensate for the movement of the space expressions, the blank spaces are removed from the replacement expression $4$2$3$1 in RegExReplace().
Multiple Punctuation in the RegEx Swap
I'm not sure how often this might occur, but it is possible that the first word is followed by as many as three punctuation marks—as in the case of the example …buttons.'" which includes a period, single quote mark and double quote mark. This can be dealt with by adding additional optional \S? expressions like so:
RegExReplace(Clipboard,"([\w']+\w)(\S?\S?\S?)(\s.*\s|\s+)([\w']+\w)","$4$2$3$1")
This will allow up to three optional punctuation marks without affecting the word swap.
On the other end it is possible that the last word will start with one or two quote marks (a double quote and a single quote "'). In this case it is probably best to use the quotes as optional characters in a new backreference:
RegExReplace(Clipboard,"([\w']+\w)(\S?\S?\S?)(\s.*\s|\s+)(""?'?)([\w']+\w)","$5$2$3$4$1")
That way any quotes encountered will remain in place during the swap. The replacement backreferences must be adjusted to account for the new subexpression $5$2$3$4$1.
Notice that there are two double quotes in the expression (""?'?). Normally a RegEx would only need one double quote, but since it is used in an AutoHotkey function delimited with double quote mark, it needs to be escaped to act as a plain double quote. In AutoHotkey this is done by placing another double quote mark in front of the original as shown. Without that addition double quote, a cryptic error will be generated when the script attempts to load.
Note: If you copy this last expression into Ryan's RegEx Tester, you may find a problem. The RegEx Tester app does not require a double quote to be escaped with another double quote. Therefore the expression is unlikely to operate properly until one of the double quotes is removed. (In the Tester, RegEx will demand a match for the first double quote.) Keep this in mind when using the RegEx Tester whenever there is a double quote in the expression. In the AutoHotkey RegEx functions all double quotes need to be escaped with a preceding double quote, although it should not appear in the RegEx Tester expression.
Tip: Another way to express the two quote marks (the double quote and single quote) which won't demand the same order is to make them alternative matches using {max,min}. By replacing (""?'?) with ([""|']{0,2}) in the function, the quote marks can be in any order (or two of the same) with a minimum of zero and a maximum of two for a match to occur. This is a little more flexible, yet serves the same purpose.
This final RegEx for swapping words may not be perfect, but it should work in the vast majority of situations. Just add the following code to your standard AutoHotkey script:
$^+F2::
Clipboard =
SendInput, ^x
ClipWait 0
If ErrorLevel
{
MsgBox, No Text Selected for Word Swap!
Return
}
Clipboard := RegExReplace(Clipboard,"([\w']+\w)(\S?\S?\S?)(\s.*\s|\s+)([""|']{0,2})([\w']+\w)","$5$2$3$4$1")
SendInput, ^v
Return
Clipboard =
SendInput, ^x
ClipWait 0
If ErrorLevel
{
MsgBox, No Text Selected for Word Swap!
Return
}
Clipboard := RegExReplace(Clipboard,"([\w']+\w)(\S?\S?\S?)(\s.*\s|\s+)([""|']{0,2})([\w']+\w)","$5$2$3$4$1")
SendInput, ^v
Return
Highlight the text from the beginning of the first swap word to the end of the last swap word and hit CTRL+SHIFT+F2. (It was discovered that the original hotkey combination !W was causing problem—most likely by an interfering system hotkey.) The two end words should reverse positions. While this RegEx may look complicated, it is far simpler than what would have been required when using the usual AutoHotkey commands discussed in the beginning of this column. That would have used many lines of code and numerous mental gymnastics. With RegEx it's all done with one line of code.
AutoHotkey Tip: An error trap (If ErrorLevel) has been added for the ClipWait command. With the parameter set to 0 the ErrorLevel routine will execute after 0.5 seconds if nothing is selected for the word swap. I recommend this code be added to any script which uses the ClipWait command.
Chapter Eight: A Simple Way to Find Out Where in the World That IP Address Is Located
“Find IP Addresses in E-mail, Documents and Web Pages, Then Automatically Locate Them!--RegExMatch()”
Have you ever wanted to know where that Spam is coming from or the geographic location of an IP address? This short AutoHotkey script extracts IP addresses from any selected text and downloads its world location from the Web.
If you're curious about where in the world that e-mail came from or want to pull Internet IP addresses out of any document or window and locate it by city, state, and/or country, then you're going to like this one. This quick little AutoHotkey app extracts any IP found in selected text, then looks up where the servers are located geographically. I call the AutoHotkey script IPFind.ahk.
One of the reasons that people don't use Regular Expressions (RegEx) more often is because it's not always easy to see where they will help. This particular application is ideal for two different uses of a RegEx. The first is extracting IP addresses from any selected text. We don't know what the addresses will be or how long they are, so it would be difficult to do with the usual AutoHotkey tools. I'm not saying it can't be done with the other AutoHotkey commands, but the code is likely to get pretty convoluted. The beauty of using a RegEx is that the parsing can be done with only one line of code. While RegEx is often mysterious to the newbie, with a little attention it's much easier than it looks.
The second use of RegEx is when the script reaches out to the Web to retrieve the IP's geographic location. A mass of data is returned and the city, state, and/or country needs to be culled out of it (if it's available). Again, while this data could be extracted with the usual AutoHotkey commands and functions, it's much easier with AutoHotkey RegEx functions.
Extracting IP Addresses from Any Document
Suppose you receive a Spam e-mail and would like to know where it came from. In many e-mail programs, you can find the originator's location by holding down the ALT key and hitting RETURN. That opens the e-mail's Property window. (You can also right-click on the message header and select Properties from the menu.) In the Details tab, the basic address and routing information is found (see Figure 1 for a Windows Live example). (In some e-mail programs you may need to view the source code which in Windows Live is the same as clicking the Message Source… button in the Properties window.)

Figure 1. In Windows Live the Details tab of the e-mail Properties window shows the sending server's IP address.
The IP address is buried inside a bunch of other chaff. The plan is to use a RegEx to extract that IP, discarding the remaining text. The first step in the AutoHotkey app will be selecting (highlighting) the target text with either CTRL+A (Select All) or by dragging the mouse over the target text while holding the left mouse cursor. (In Windows Live Properties window above, CTRL+A doesn't work, so you will need to drag the mouse to select.)
Once the text is selected, the following AutoHotkey script will find and display the IP:
^!I::
Clipboard =
SendInput, ^c
ClipWait 0
If ErrorLevel
{
MsgBox, No Text Selected!
Return
}
FoundPos := RegExMatch(Clipboard, "\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b" , IPAddress)
MsgBox %IPAddress%
Return
Clipboard =
SendInput, ^c
ClipWait 0
If ErrorLevel
{
MsgBox, No Text Selected!
Return
}
FoundPos := RegExMatch(Clipboard, "\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b" , IPAddress)
MsgBox %IPAddress%
Return

When this AutoHotkey script runs after selecting the text in Figure 1, the pop-up message shown on the left appears displaying the first IP address—if any.
After loading the script, the hotkey combination CTRL+ALT+I , I for IP, (^!I) is used to activate the routine. The first step is to clear the Clipboard (Clipboard =). This makes it possible to later use the ClipWait command, which needs an empty Clipboard to work properly, rather than an arbitrary Sleep command time interval to pause the script while the Clipboard loads. When 0 is added as a parameter to ClipWait, the command times out after 0.5 seconds if nothing is placed in the Clipboard and sends an error. (The value of the parameter could also be any number of seconds.) This is added to prevent the command from waiting indefinitely whenever nothing has been preselected. The error routine displays the message "No Text Selected!" in a pop-up window.
This AutoHotkey snippet uses the Windows copy hotkey, CTRL+C, SendInput, ^c to capture the selected text into the Windows Clipboard and the ClipWait command pauses until there is data detected in the Clipboard.
The RegExMatch() function is used to find the first IP address in the stored Clipboard text (RegExMatch(Clipboard, "\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b" , IPAddress)).
Note: At this point in the scripts evolution, the result of this RegExMatch() function does not need to be set equal to FoundPos, but in later iterations FoundPos—the starting position of the matched string—will be needed. In this example, calling the function by itself:
RegExMatch(Clipboard, "\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b" , IPAddress)
would suffice since it stores the matched text from Clipboard to the variable IPAddress.)
This RegEx is relatively simple since IP addresses use a repeating pattern. Each IP consists of four sets of numbers separated by a dot. Each number is a range between 0 and 255. Each set must have at least one digit and no more than three. Since we only need to identify the pattern for purposes of extracting the match it's unlikely that the RegEx will need to restrict the numbers to between 0 and 255. It would be rare to find a pattern that fits the four numbers with the three separating dots which isn't an IP address. For example, the current expression would see "597.34.201.99" as a match even though "597", which is not between 0 and 255, would not be found in any IP address—but that is unlikely to occur. At the end of the chapter, a RegEx which accounts for this discrepancy and does complete IP validation is offered, but for now the current expression will do the trick.
The heart of this RegEx is the \d{1,3} repeated four times. The \d is the expression for any digit (0-9). The following {1,3} operator tells RegEx to use the previous match at least once and no more than three times in a row.
Since the dot (.) is normally a RegEx wildcard (match any character), it needs to be escaped with a backslash (\) when only a dot should be matched. Thus \. means a dot must follow the number to continue the match. This is inserted two more times for a total of three dots \d{1,3}\. between the four sets of digits. The string is terminated with the digit pattern \d{1,3} making a total of four.
The entire expression is bound with word expression \b at the beginning and end. This prevents the pattern from being recognized within another word. It can be at the start of a string, at the end, or next to any type of punctuation.
RegEx Tip: Since the same pattern is repeated three times, the expression above can be shortened in the following manner:
FoundPos := RegExMatch(Clipboard, "\b(\d{1,3}\.){3}\d{1,3}\b" , IPAddress)
By enclosing the repeated expression in parentheses (\d{1,3}\.) and following it with {3}, the expression is repeated three times (\d{1,3}\.){3} thus shortening the line of code.
Matching More Than One IP Address
Since we started accepting PayPal on the ComputorEdge E-Books Web site, there are many orders with no address information. This is because PayPal protects the consumer's information by authorizing and processing the payment directly on its own site. The address information is not important from a business point of view because we have no intention of doing anything with it, but I am curious where the orders originate worldwide. Many of the ComputorEdge E-Books orders come from areas outside the United States. Information which is captured includes the e-mail address (needed to deliver the download links), name, and IP address. The plan is to use the new IPFind.ahk script to query the home country of any order by using the IP. Plus, it would be convenient to query a group of IPs at the same time. To do that the app needs to find all of the IP addresses in any selected text (see Figure 2).

Figure 2. The text is selected from a group of orders listed at the ComputorEdge E-Books shopping cart site which includes multiple IP addresses.
Due to the design of many Web pages, selecting multiple items usually includes many other unwanted sections. But using a RegEx makes it possible to pick out the relevant data. The key now is to find all of the IPs—not just one.
The RegExMatch() function above only finds the first match in a string—then stops looking. If you want to find all of the matching strings (in this case IP addresses), then it's necessary to put the snippet of code in a loop and adjust the starting position in the string after each match found. This is the point at which the variable result FoundPos is used:
^!I::
Clipboard =
SendInput, ^c
ClipWait 0
If ErrorLevel
{
MsgBox, No Text Selected!
Return
}
CountIP := 1 ; counts the number of IPs found
Next := 1 ; used as the position to start the next match search
Loop
{
FoundPos := RegExMatch(Clipboard, "\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b", IPAddress%CountIP%, Next)
Next := FoundPos + StrLen(ipaddress%CountIP%)
If FoundPos = 0
Break
CountIP++
}
Clipboard =
SendInput, ^c
ClipWait 0
If ErrorLevel
{
MsgBox, No Text Selected!
Return
}
CountIP := 1 ; counts the number of IPs found
Next := 1 ; used as the position to start the next match search
Loop
{
FoundPos := RegExMatch(Clipboard, "\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b", IPAddress%CountIP%, Next)
Next := FoundPos + StrLen(ipaddress%CountIP%)
If FoundPos = 0
Break
CountIP++
}
There are two new variables added to the script. The first variable is CountIP which is used to keep track of each IP address found and save it in the variable IPAddress%CountIP%—which creates a pseudo-arrays of the IPs (e.g. IPAddress1, IPAddress2, IPAddress3,…). This set of variables will be used later in the Internet look up of each IP location.
The second variable is Next which calculates the starting position of each new match search in the text. The Next parameter in the RegExMatch() function shown is the point at which the RegEx will begin searching in the text string. Without this incrementing parameter, the function would always return the same first IP and result in an infinite loop.
Notice that the Loop command does not include any parameter to tell it how many times it should repeat. That means that inside the loop, there must be a way to escape or break out of the Loop. Otherwise, the Loop continues endlessly (or until the process is killed). That's the purpose of the following:
If FoundPos = 0
Break
Break
The variable FoundPos, the result of the RegExMatch() function, contains the starting position of any RegEx match found. If the result is 0, then no match was found in the string. Eventually, as the script works through the text string, there will be no match and FoundPos will equal 0. Then the loop will Break continuing the script. This prevents an infinite loop.
After a match is found, the starting position for the next match search in the next loop iteration must be calculated and stored to the variable Next. The new starting position is the sum of the last starting position plus the length of the last matched string (Next := FoundPos + StrLen(ipaddress%CountIP%)) using the StrLen() function to calculate the IPs length. Once no more matches are found in the remaining string portion, FoundPos is set to 0 and the loop breaks.
AutoHotkey RegEx Tip: As mentioned in Chapter Five, there is an option in RegExMatch() which will save object data by preceding the RegEx with O) (uppercase O followed by the close parenthesis). This MatchObject) saves the object properties and returns the position, length, value and a few other properties in Object Oriented Programming (OOP) format. To test the results you can write your own simple AutoHotkey test script such as:
Haystack := "Abby has always been absent from the abbey."
FoundPos := RegExMatch(Haystack, "O)(absent)", newvariable)
MsgBox % FoundPos " " newvariable.Value[0] " " newvariable.Pos[0] " " newvariable.Len[0]
FoundPos := RegExMatch(Haystack, "O)(absent)", newvariable)
MsgBox % FoundPos " " newvariable.Value[0] " " newvariable.Pos[0] " " newvariable.Len[0]
You should be able to use these variables directly in the Loop for incrementing the search, although I don't immediately see a major advantage in this example, but there are probably other applications where it would be ideal to use this option. (These results will not display in Ryan's RegEx Tester.)
The operator CountIP++ is an abbreviated method for expressing CountIP := CountIP + 1 and is the same as CountIP += 1 each of which increment the variable CountIP by one. This is used for both counting the number of IP addresses found and creating the pseudo-array variable IPAddress%CountIP% in the next iteration of the loop.
The matched IP addresses are now saved in the pseudo-array IPAddress%CountIP%. Before displaying them in a message box we want to look up the location of each.
Finding the IP Address Location
If you type "lookup 72.80.151.32" into a Google search, you get a list of sites for getting more information about a particular IP. I perused a few of these sites and finally decided to use this IP Address Lookup (see Figure 3) as the resource site for retrieving the geographic location of the IP with the FindIP.ahk script. I probably could have used almost any other site, but this one seemed good enough. It includes a fairly complete list of city, state, and country (when available).

Figure 3. This IP Address Lookup site shows the location of the server when an IP is entered into the search field.
All we need for an IP lookup is the format of the Web site's search URL. In this case the following finds the IP 72.80.151.32 on the selected site:
http://ip-address-lookup-v4.com/lookup.php?host=ip-address-lookup-v4.com&ip=72.80.151.32&x=31&y=29
This URL string is found by manually doing any IP search with the built-in search field, then copying the address line in the URL window of the browser. The only part of the URL which will need to change for a new search is the IP address (72.80.151.32) marked in bold in the URL above.
Note: The Web site I selected does not always deliver a result for city, state, and/or country. There may be other sites with more complete information. If so, then similar techniques as those shown here can be used to download the data.
The trick now is pulling the pertinent data from the Web site without being forced to open the page in a Web browser, then entering the new IP address for each IP. This could become tedious, especially if we selected the city, state, country data in each page with a mouse. Fortunately, there are AutoHotkey techniques which allow the retrieval of Web page data without ever opening the page in a Web browser.
Pulling Data From a Web Page Without a Web Browser
One such AutoHotkey feature for retrieving data from the Internet is the UrlDownloadToFile command. This command allows a script to download a Web page and save it in a file, But what is actually downloaded is not what you see in a Web browser, but the source code which the browser interprets—all of it in text in the form of HTML code. For example, the source code for the Web page shown in Figure 3 is the code shown in Figure 4.

Figure 4. Source code is interpreted to create the Web page shown in Figure 3. Only the highlighted text is pertinent to the IPFind app.
The fact that the source code is all text makes the job easier. After inspecting the code in Figure 4, it's easy to see markers which can be used with the RegExMatch() function to extract the city, state, and/or country. It is quickly noted that in every search result page the target words are preceded by the word/code combination Near: <span class="blueish"> and followed by the </span> HTML code. That is all we need to know to write a RegEx which will extract the data:
RegExMatch(WebPageData, "Near: <span class=""blueish"">(.*)</span>", Location)
By using the unique words and text as keys for finding the data the wildcard .* captures everything between the starting keys and ending keys, then stores it in the variable Location. This is demonstrated by using Ryan's RegEx Tester shown in Figure 5.
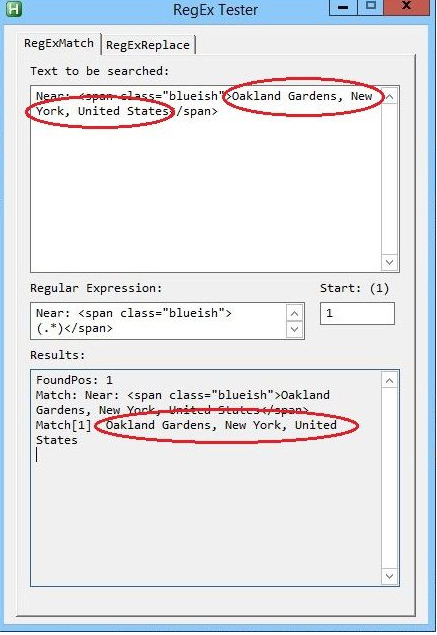
Figure 5. The RegEx Tester shows how to capture data specific data from the source code for a Web page by using the hard coded words and HTML as markers.
Rather than use the UrlDownloadToFile command, I opted for the little more enigmatic example for downloading the Web page directly to a variable shown on the same documentation page. If I had used the cited command, then the script would first save the data into a file, then need to read it back into a variable for parsing. That would add disk access time to the process and was unnecessary since none of the downloaded data would be saved in its original form. I turned the code into a function (GetLocation()) which can be reused for each IP found in the original text:
GetLocation(FindIP)
{
IPsearch := "http://ip-address-lookup-v4.com/lookup.php?host=ip-address-lookup-v4.com&ip=" . FindIP . "&x=31&y=29"
whr := ComObjCreate("WinHttp.WinHttpRequest.5.1")
whr.Open("GET", IPsearch)
whr.Send()
Sleep 100
version := whr.ResponseText
RegExMatch(version, "Near: <span class=""blueish"">(.*)</span>", Location)
Return Location1
}
{
IPsearch := "http://ip-address-lookup-v4.com/lookup.php?host=ip-address-lookup-v4.com&ip=" . FindIP . "&x=31&y=29"
whr := ComObjCreate("WinHttp.WinHttpRequest.5.1")
whr.Open("GET", IPsearch)
whr.Send()
Sleep 100
version := whr.ResponseText
RegExMatch(version, "Near: <span class=""blueish"">(.*)</span>", Location)
Return Location1
}
I would like to state that this function is self-explanatory, but it isn't. Suffice it to say that I copied it from the online documentation and modified the pertinent parts for the purposes of the IPFind.ahk script. I created the variable IPsearch to store the URL of the Web page. Notice that the variable FindIP is the IP address fed to the function by the main script. IPFind is concatenated (inserted) inside the URL discussed above so the page for that specific IP will be downloaded.
While I have previously used the ComObjCreate() function in other scripts (mostly copied from scripts found on the AutoHotkey Forum), I don't have enough of an understanding of how everything fits together to offer a precise explanation. (That may come at sometime in the future when I dedicate time to figuring out how ComObject works in AutoHotkey.) For now all I can say is it works and downloads a Web page to the variable version. I did add the Sleep command to pause the script since an Internet download can take a little time. If you find that you are getting no results for an IP that should work, then try increasing the Sleep time.
The RegExMatch() function stores the first backreference (the matched data within the parentheses) in the first array variable Location1. If there were more backreference (sets of parentheses), then they would be stored in successive variables (Location2, Location3, …). This value (the location of the IP address) is returned to the main script.
Displaying the Results
In order to display the results another Loop command is used to piece together the information:
If IPAddress1
{
IPList := ""
CountIP--
Loop, %CountIP%
{
CheckIP := IPAddress%A_Index%
WhereIs := GetLocation(CheckIP)
If StrLen(CheckIP) < 11 ; to align columns for different length IP addresses
Tab := "`t`t"
Else
Tab := "`t"
IPList := IPList . IPAddress%A_Index% . Tab . WhereIs . "`r"
}
}
Else
IPList := "No IPs Found!"
MsgBox %IPList%
{
IPList := ""
CountIP--
Loop, %CountIP%
{
CheckIP := IPAddress%A_Index%
WhereIs := GetLocation(CheckIP)
If StrLen(CheckIP) < 11 ; to align columns for different length IP addresses
Tab := "`t`t"
Else
Tab := "`t"
IPList := IPList . IPAddress%A_Index% . Tab . WhereIs . "`r"
}
}
Else
IPList := "No IPs Found!"
MsgBox %IPList%
This snippet of the AutoHotkey script loops through the list of IP addresses found and uses the GetLocation() function explained above to look up the server's geographic location for each. The IP and location are concatenated to the list (IPList) which is displayed in a MsgBox. If there are no IPs found, then "No IPs Found!" is displayed. CountIP— is used to decrease itself by 1 before starting the loop since the previous loop added one extra for the last non-existent IP. Other than these notes, the techniques used here have been addressed before in previous books.
The final display of the IPs appearing in Figure 2 and their locations are shown in Figure 6.
Figure 6. IP addresses appearing in Figure 2 and their geographic locations.
The final code for the IPFind.ahk script and a compiled version, IPFind.exe, can be found in the ZIP file IPFind.zip and downloaded from the ComputorEdge AutoHotkey Dropbox download site.
A Complete Regular Expression (RegEx) for Validating IP Addresses
For the purposes of the IPFind app, the RegEx used here is probably adequate. The chance of it matching a sequence which isn't a valid IP is pretty low. Even then, it merely returns a blank location. However, if you are validating an IP for an online form or some other use where you need to prevent errors, then you must ensure it is at least a possible IP address. That means the numbers can only run from 0 to 255 in each numeric part. Doing that involves a little more complicated RegEx:
^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$
This expression (copied from another source) insures that each number is within the range 0 to 255. Every operator in this RegEx is discussed in this book—except the ?: operator, which can be found in the online AutoHotkey RegEx Quick Reference. The effect of adding ?: as the first two characters inside a set of parentheses is to prevent the matched data from becoming captured as a subpattern. In expressions using backreferences this operator may be an important tool.
Chapter Nine: Stripping Out HTML Tags
“How to extract and save the text from a web page--RegExReplace()”
Learn how to strip HTML tags from Web pages with AutoHotkey RegEx.
Stripping Out HTML Code from a Web Page
If you look underneath the hood of a Web page, you will find numerous codes (called tags) from the HTML language. HTML is what makes the page display properly in a Web browser. But what if you wanted to save all the text in a Web page without the code?
A simple way to do that is highlight the entire rendered page (what you see in your Web browser—not the source code), copy, then paste it into a program such as Notepad. This may be the most common technique used and easiest if that's all you want. However, there may be other uses for the plain text from a Web page such as extracting links or finding e-mail addresses.
In this chapter I look at using Regular Expressions (RegEx) in AutoHotkey to work with Web pages. First, a short script is developed for stripping all HTML from a Web page's source code.
In this example, I use the HTML file of one of Wally Wang's columns (see Figure 1) to demonstrate how to remove HTML code.

Figure 1. A Web page is loaded to get access to the HTML code.
Figure 2. When viewing the source code the HTML tags are seen.
Notice that all of the HTML tags start with the left pointing arrow (< ) and end with the right pointing arrow (>). These delimiters will be the keys used to removing the tags from the remaining text. The final result will look like the text file opened in Notepad shown in Figure 3.

Figure 3. The final result is a text file with no HTML code.
Two features of AutoHotkey are used in this example to first download the Web page (UrlDownloadToFile), then remove all of the HTML tags (RegExReplace()). The UrlDownloadToFile command is included to show how it works, but the download to variable technique in the last chapter would have worked just as well. The UrlDownloadToFile command is more straightforward than that alternative.
I must confess that I struggled a little with this Regular Expression. Although the solution was not obvious to me, when the light finally turned on, it was remarkably simple. It's a cool technique which requires a little negative thinking. I'll explain more about my ordeal below.
The script I put together requires first selecting (highlighting) the URL (usually in the address bar of a Web browser—although it could be in any document). After hitting the hotkey combination (CTRL+ALT+Q), that address is automatically copied to the Clipboard for downloading the Web page to a file (UrlDownloadToFile). The file is then read (FileRead command) into a variable for stripping out the HTML tags with a RegEx function (RegExReplace()). The final result is saved to a file (FileAppend command) and opened in Notepad with the (Run command):
^!q::
Clipboard =
SendInput, ^c
ClipWait 0
If ErrorLevel
{
MsgBox, No URL Selected!
Return
}
UrlDownloadToFile, %Clipboard%, URLtemp
FileRead, URLtemp, URLtemp
StringReplace, URLtemp, URLtemp, <br>, `r`n, , All
NoHTML := RegExReplace(URLtemp,"<[^>]+>")
FileDelete, Webtext.txt
FileAppend, %NoHtML%, Webtext.txt
Run, NotePad Webtext.txt
Return
Clipboard =
SendInput, ^c
ClipWait 0
If ErrorLevel
{
MsgBox, No URL Selected!
Return
}
UrlDownloadToFile, %Clipboard%, URLtemp
FileRead, URLtemp, URLtemp
StringReplace, URLtemp, URLtemp, <br>, `r`n, , All
NoHTML := RegExReplace(URLtemp,"<[^>]+>")
FileDelete, Webtext.txt
FileAppend, %NoHtML%, Webtext.txt
Run, NotePad Webtext.txt
Return
This script uses the same Clipboard technique for copying the selected text discussed in last chapter for looking up IP address locations. This time the Clipboard content is the URL of the Web page used in the UrlDownloadToFile, %Clipboard%, URLtemp line of code. URLtemp is the name assigned to the new downloaded file.
Once the file is downloaded, it is read into the variable URLtemp (FileRead, URLtemp, URLtemp). (Note: Both the filename and the variable name are the same URLtemp. This is not a problem as long as one is a file and the other is a variable. However, if you use the same name for two different files or two different variables, then you're likely to encounter problems. In most cases it is better to use separate, more descriptive names to prevent conflicts and make the script easier to understand.)
The HTML tag <br> is used to place a new line (break) in a Web page. If all the tags are removed without first substituting regular new lines in the text, then the entire file will become one huge paragraph with no breaks. To deal with this problem, the StringReplace command is used to replace all of the <br> tags with a carriage return `r and linefeed `n (new line). While the RegExReplace() function could be used, in many cases where there the search value is constant the StringReplace command is preferable to using a RegEx. (It's faster.) However, you must know what you're looking for with StringReplace as in the case of the <br> tag. There are so many possible HTML tags that it would be unwieldy to use StringReplace for removing all the tags—although it could be done by searching for the occurrences of the < and > keys.
The HTML Tag RegEx
As I mentioned above, I had a tough time with this one. For quite a while I was attempting to capture all of characters after the first < sign with the wildcard .* which adds any character encountered. However, this would plow through the entire file until it encountered the last > sign, thereby deleting almost everything else, as well as any HTML tags. I needed to force the RegEx to stop when it encountered the next > sign. It turned out to be quite simple.
By including all of the characters which are not the > sign ([^>]+), the RegEx continues until it encounters the > sign. RegEx stops, but voil? the next character is the > sign completing the match. Don't forget that the ^ when placed within inside a range negates the characters in that range. Rather than looking for a match, RegEx looks for characters which don't match. Sometimes it's more important to know what it's not, than what it is. (The ^ is also the anchor for the beginning of a line, but when used within a range, square brackets […], it means not.)
The line of code NoHTML := RegExReplace(URLtemp,"<[^>]+>") strips any remaining HTML tags out of URLtemp. The new variable with the HTML tags removed by RegExReplace() is called NoHTML.
Note: This problem of consuming all the text until the last > sign is caused by the default action of RegEx called greed and discussed in more detail below.
You may wonder what happens if the greater than > or less than < sign are used within the text of the Web page…say for a mathematical formula? That's not a problem because within the HTML source code those signs are represented by > and < respectively and would never be a match for the RegEx.
The remainder of the script deletes the old file (FileDelete, Webtext.txt), saves the new file (FileAppend, %NoHtML%, Webtext.txt), then opens the new file in Notepad (Run, NotePad Webtext.txt). Use the stripped data however you like.
Hungry, Hungry RegEx: Greed
In this problem of removing HTML tags, I ran into the default action of RegEx greed. When I used the RegEx <.*> it wiped out all of the HTML tags and everything in between. Yes, it found the first > closing tag, but ignored it and all of the other > signs until it reached the last one. Referred to as greed, this is the way RegEx is supposed to work, but was not what I wanted.
From the AutoHotkey RegEx Quick Reference, "By default, *, ?, +, and {min,max} are greedy because they consume all characters up through the last possible one that still satisfies the entire pattern." While often not coming into play, greed is an important concept. It only applies to those modifiers which repeat previous matches.
I resolved the problem by continuing the matching as long as one of the characters was not the > sign (<[^>]+>). Then it picked up that same > sign not previously matched as the last character. This works to eliminate the problem of greed (gobbling up everything between the two signs < and >), but there may be times when this negative approach is not an option.
To eliminate the greed behavior follow the affected operator (*, ?, +, or {min,max}) with the question mark (?). Then, rather than finding the last possible match, the first possible match is used. For example the RegEx <.*?> eliminates the greed in .* and returns the first match. That means the line of code:
NoHTML := RegExReplace(URLtemp,"<[^>]+>")
from the script can be replaced with:
NoHTML := RegExReplace(URLtemp,"<.*?>")
returning the same result by removing all HTML tags.
Part of what makes Regular Expressions confusing is that the same symbol may have a different meaning depending upon how it's used. The question mark based upon its location in the RegEx may indicate that a character is either optional a?, that greed should be turned off a+? to match the first occurrence, or, if used with the colon inside the first parenthesis (?:[abc]+) do not assign a subpattern. Plus the question mark is integral to look-ahead and look-behind assertions (Chapter Twelve).
Note: You may have notice that sometimes I use the asterisk * to continue matching while other times I use the plus + sign. The two are practically interchangeable except in one way. The asterisk * will always match at the beginning of a string (zero or more), even if there is no matching character. The plus + sign only matches if the character is found (one or more). Put another way the plus + sign demands a match while the asterisk * isn't so picky. In most cases it probably won't make much difference which you use, but there are times when it will matter. For example, when matching a row of letters in the string baaaa, a* matches at the first character even though there is no a thus returning nothing, while a+ matches at the second character returning aaaa. There are times when whether you use * or + will make a difference.
There is more to do with RegEx and HTML tags, such as finding the matching tags (open and close) and extracting data. In the next chapter, we'll look at extracting links from HTML tags.
Chapter Ten: An App for Extracting Web Links from Web Pages
“Web Link Extractor AutoHotkey Scripts--RegExMatch()”
Need to save Web links from Web pages? Here are two AutoHotkey scripts which do the job.
Pulling External Links from Web Pages
Have you ever wished that you could download all the Web links from a Web page without right-clicking on each link and individually copying the URL? Now you can with AutoHotkey and Regular Expressions (RegEx)! In our continuing saga which explores the mysteries of RegEx, we turn to parsing URLs for external Web links from any page and saving them to a file. All that's required is the highlighting of the URL in the address field of a Web browser (see Figure 1) and using the hotkey combination CTRL+ALT+L (^!l in AutoHotkey code).

Figure 1. Highlight the URL in the address field of the target Web page, use the hotkey combination, and the external links will be written to a file.
The AutoHotkey script LinkFind.ahk, reaches out to the Web page, downloads the source code, then extracts the links from the code using an AutoHotkey RegEx. The data is then written to a text file and opened in Notepad (see Figure 2). You can either use the data directly or save it with another file name.
Figure 2. The extracted links are written to a text file then opened with Notepad.
Note: The effectiveness of this app depends upon the formatting of the Web page. Some Web pages use frames or call external files which won't appear in the source code. In those situations, the results will be limited to those links which appear at the top level.
The LinkFind AutoHotkey Script
This script is in some ways similar to the one in the last chapter where we stripped all the HTML tags from a Web page creating a text file, as well as, Chapter Eight where the script extracted IP addresses and looked up their geographic locations. Here is the entire LinkFind.ahk script:
^!l::
; Section 1: highlighted the URL copied and downloaded to URLtemp
Clipboard =
SendInput, ^c
ClipWait 0
If ErrorLevel
{
MsgBox, No Text Selected!
Return
}
UrlDownloadToFile, %Clipboard%, URLtemp
FileRead, URLtemp, URLtemp
; Section 2: Loop extracting and writing links to variable LinkList
LinkList =
Next := 1
Loop
{
FoundPos := RegExMatch(URLtemp, "<a.+?href=""(https?.+?)"".*?>(.+?)</a>" , Link, Next)
If FoundPos = 0
Break
Else
{
LinkList := LinkList . Link2 . "`n" . Link1 . "`n`n"
Next := FoundPos + StrLen(Link)
}
}
If LinkList !
LinkList := "No External Links Found!"
; Section 3: delete old file, write new file, and open with Notepad
FileDelete, LinkText
FileAppend, %LinkList%, LinkText
Run, Notepad LinkText
Return
; Section 1: highlighted the URL copied and downloaded to URLtemp
Clipboard =
SendInput, ^c
ClipWait 0
If ErrorLevel
{
MsgBox, No Text Selected!
Return
}
UrlDownloadToFile, %Clipboard%, URLtemp
FileRead, URLtemp, URLtemp
; Section 2: Loop extracting and writing links to variable LinkList
LinkList =
Next := 1
Loop
{
FoundPos := RegExMatch(URLtemp, "<a.+?href=""(https?.+?)"".*?>(.+?)</a>" , Link, Next)
If FoundPos = 0
Break
Else
{
LinkList := LinkList . Link2 . "`n" . Link1 . "`n`n"
Next := FoundPos + StrLen(Link)
}
}
If LinkList !
LinkList := "No External Links Found!"
; Section 3: delete old file, write new file, and open with Notepad
FileDelete, LinkText
FileAppend, %LinkList%, LinkText
Run, Notepad LinkText
Return
Programming Note: When I originally wrote this snippet I used two Loops. One for parsing the links into a pseudo-array of variables, then another to write all the variables to a text file. While this was good for debugging and worked fine, the code became much more convoluted than necessary. In this version, the second Loop is combined with the first, immediately writing all the data to one variable LinkList. This effectively eliminated the need for the pseudo-array of variables and cut the number of lines of code by two thirds. The snippet above could be further reduced by eliminating the interim variable LinkList and writing directly to the file within the Loop with the FileAppend command. As a matter of good script writing practice, minimize the number of Loops and eliminate intermediate steps whenever possible. But don't worry if you don't get it right on the first try. Often how to clean up and reduce code is not obvious until after you have written your first working script.
There are three basic sections to the script which is initiated with the hotkey combination CTRL+ALT+L (^!l). In the first section, the highlighted URL is copied to the Windows Clipboard (SendInput, ^c), the script pauses until data is detected in the Clipboard (ClipWait 0), then the Clipboard contents is used to download the source code of the target Web page to the file URLtemp (UrlDownloadToFile, %Clipboard%, URLtemp).
In the second section, a Loop uses a RegEx to extract the links. This Loop is very similar to the one used to extract IP addresses in the IPFind.ahk script discussed in Chapter Eight. (The IPFind.ahk script is an example of code which uses two loops which could most likely be combined into one.) Of primary interest here is how the RegEx works.
The HTML tags for Web links are <a href="URL">Link Text</a>. That means all the HTML links found in the Web page source code will be surrounded with the tags shown. Plus, external links will include either http:// or https:// within the quotes after the href=. To match those links the following RegEx is used:
FoundPos := RegExMatch(URLtemp, "<a.+?href=""(https?.+?)"".*?>(.+?)</a>" , Link, Next)
This RegEx does a pretty good job of finding external links within the Web page source code. To breakdown the RegEx, we always start at the left end.
The first two characters <a tell RegEx to start matching whenever these characters are encountered.
The following .+? is the wild card meaning at least one or more of anything .+, but in the non-greedy mode ? consuming only enough to find the first possible match rather than all possible matches (as discussed in the last chapter). This wildcard is necessary since HTML doesn't care which order parameters occur inside the two arrow brackets. While the href for the link will normally occur right after the <a and a space, this is not always the case. Any other intervening parameters must be ignored until the first href is encountered.
That first match at the occurrence of href=""(https?.+?)"" continues the process. If there is no href or http(s) then the match fails since there will not be an external link. Using https? (the s is optional when followed by a question mark ?) ensures that the link found is not merely an internal Web page jump. Note that the double quote mark is escaped in AutoHotkey functions with another double quote mark (""). The URL is located between the two double quotes and saved as the first sub-pattern or sub-reference as indicated by the set of parentheses. The first sub-reference is saved in the variable Link1. Again the .+ in the non-greedy mode ? consumes all characters until the next double quote is encountered ("").
Reminder: To test this expression in Ryan's RegEx Tester, remove the extra double quotes.
Since there may be more HTML parameters inside the arrow brackets after the URL, the .* wildcard is used in the non-greedy mode ? this time matching none or more characters until the closing arrow bracket > is encountered. This illustrates the importance of the difference between the .+ wild card which demands one or more characters and the more lenient .* wildcard which will also match no character at all. In many HTML tags the closing arrow bracket might occur immediately after the closing double quote for the href—not even a space. In that situation, using .+ which demands at least one character could cause the match to fail.
The second sub-pattern or sub-reference (.+?) is the text (link label or name) between the first HTML tag <a ….> and the closing HTLM tag </a> and saved in the variable Link2. Again the question mark ? is used to activate the non-greedy mode which will the stop matching when the first </a> is encountered.
Link is the variable where the entire match is saved. The sub-references are saved in Link1 and Link2 respectively. If there were more sub-references (RegEx operators within parentheses) they would be saved in additional array variables (Link3, Link4, …).
The extracted link names and URLs are added (concatenated) to the variable LinkList:
LinkList := LinkList . Link2 . "`n" . Link1 . "`n`n"
The newline character `n is used to separate the links in the final list.
See Chapter Eight and IPFind.ahk for more details on how the remainder of this section of the script works including the use of the variable FoundPos for breaking out of the Loop.
In Section 3 of the script, the old file is deleted (FileDelete, LinkText), the new file is created (FileAppend, %LinkList%, LinkText), then opened with Notepad (Run, Notepad LinkText). If you want to keep the data, save it with a new file name.
As I kept working on this RegEx, I found more ways to improve it. Of critical importance is understanding the difference between greedy and non-greedy when using wildcards.
Chapter Eleven: Verifying E-mail Addresses with AutoHotkey
“How e-mail address checking works with AutoHotkey RegEx.”
There are plenty free Regular Expression (RegEx) examples on the Web. The problem is that they do not all work as advertised.
One of the best uses of Regular Expressions (RegEx) is for checking the formatting of data—especially e-mail addresses which can be particularly difficult to type without making errors (unless a person is using AutoHotkey hotstring substitution). By using RegEx in AutoHotkey, script writers can eliminate many user errors (a bad e-mail address) which can cause problems down the line. If the formatting does not match, the data is not accepted.
In this chapter I look at a Regular Expression for validating e-mail addresses and break the expression down to understand what it does and possible deficiencies. I found this one on the Web and copied it as an example. However, as I started to analyze the RegEx I saw that it fell short in a number of areas. I made some adjustments to improve it, but ultimately needed to switch to another one. (I spend time here on this particular RegEx because sometimes it's just as important to understand how something doesn't work as how it does.)
A second RegEx (discussed later in this chapter) I took from the ComputorEdge Web page for signing up for e-mail subscriptions. I wrote this RegEx a number of years ago in JavaScript. (I most likely copied it from another long forgotten source.) While it serves the same purpose, it's cleaner and more comprehensive than the first RegEx.
Testing a RegEx
The only way to truly learn how Regular Expressions work is to test them. I've used the following short AutoHotkey script to run various RegEx expressions:
Haystack := "jackdunning@computoredge.com"
FoundPos := RegExMatch(Haystack, "^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$", newvariable)
Msgbox %FoundPos% %newvariable%
FoundPos := RegExMatch(Haystack, "^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$", newvariable)
Msgbox %FoundPos% %newvariable%
This snippet could be more elegant by adding a GUI with two input fields, but editing the script with Notepad is almost as quick. It's just a matter of changing the input (Haystack) or the RegEx (found between the two double quotes) in the RegExMatch() function, saving the file, right-clicking on the filename in Windows Explorer, then selecting Run Script. If the RegEx is valid the e-mail address displays in the message box. If not, it displays 0 (see Figure 1).

Figure 1. If the e-mail validation routine works, the message box displays the address. If not, the message box displays zero.
If you keep your text editing and Windows Explorer windows open and side-by-side, then it is easy to make changes, then test the RegEx. Everything discussed in this chapter can be found in the AutoHotkey RegEx Quick Reference.
Note; I wrote this chapter early in my learning process before I started using Ryan's RegEx Tester discussed in previous chapters. This short script is an effective RegEx test, but does not have the power of Ryan's Tester. In most cases I would use Ryan's app, but on occasion embedding a short line or two of code similar to these shown in a new script may help in debugging. Plus, as discussed in the tip in Chapter Five under "RegEx Options (Ignore Case)", there are times when Ryan's RegEx Tester will not provide you all of the results you want. For example, when using the MatchObject option O) the various object properties will not be displayed in Ryan's RegEx Tester.
RegEx E-mail Address Validator Number One
The first RegEx for testing e-mail addresses which I found somewhere on the Web is as follows:
FoundPos := RegExMatch(Haystack, "^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$", newvariable)
It was not written for AutoHotkey, but operates in almost the same manner. Here is how it works.
The caret ^ found at the beginning of the expression is a beginning (or front end) anchor. That means there must be a match at the beginning of the string to be valid. If not, the RegEx will fail (return 0). This prevents the match from starting somewhere inside the data string.
Looking at the end of the RegEx we see the $ character.The dollar sign $ found at the end of the expression is an end (or terminating) anchor. That means there must be a match at the end of the string to be valid. If not, the RegEx will fail (return 0). This prevents the match from ending somewhere inside the data string. Between the circumflex (^) and dollar sign ($) a RegEx can be completely enclosed to ensure that there are no improper characters at either the beginning or end of the expression.
Tip: If you want to use the expression to extract e-mail addresses from a text page such as the source code for a Web page, then removing the beginning and ending anchors should do the job—although I did not run this test.
The parentheses "(…)" creates a group which may indicate order of evaluation, capture special features, or change options. Unfortunately, these particular sets of parentheses appear to serve no purpose in this RegEx. Remove them and it works the same way. In the second RegEx (discussed below) the parentheses serve an important purpose.
The first range [a-z0-9_\.-]+ accepts any lowercase letters, numbers, the underline mark, dots, and hyphens. The plus sign + tells the RegEx to continue accepting the characters within the preceding range until something not in the range is encountered—in this case, either an invalid character or the @ sign. (Note: The backslash \ used to escape the dot is not required within a range in AutoHotkey. Only characters with special meaning within a range require escaping to serve as a raw character. The RegEx range works in the same manner with the backslash removed.)
Since the @ sign is on its own, it is required somewhere in the e-mail address (and only once) to be valid. This is the most useful feature of this RegEx since every e-mail address must contain the @ character.
After the @ sign, the RegEx [\da-z\.-]+ matches the same range as was use in the first range, lowercase letters and digits, plus the dot and hyphen, but no underline mark. For some reason, \d was used in place of 0-9 which both mean the same thing.
The RegEx \.([a-z\.]{2,6})$ is supposed to determine the end ($ anchor) of the e-mail address (extensions such as .com, .org, or .uk). However, it appears to have an error. The first single dot \. matches the require dot before the extension, but including it again in the following range not only allows double dots, but the entire address could end with a dot—which would never be found in an e-mail address. The \. within the range should be removed to prevent dots at the end of the address.
The {2,6} following the range tells the RegEx that the minimum number of characters accepted from the preceding range is 2 and the maximum number is 6. This ensures that the e-mail address extension is at least two letters and no longer than six letters.
The problems with this RegEx continue. It is still possible to start the e-mail address with a dot, have a dot appear before or after the @ sign, and double dots may occur anywhere within the e-mail address. It turns out that this RegEx is not nearly as useful as I thought. I did add [^\W] to the beginning of the RegEx to prevent any non-alphanumeric characters from occurring at the beginning of the e-mail address. (\W with a capital W means any non-alphanumeric character.) When \W is preceded with the caret ^ inside the range it means not (anything except those characters), but this is a double negative. The double negative works, although an easier way to express it is [\w] (lower case w) which accepts only an alphanumeric character.
I also added [^.] just before the @ character to prevent a dot at that location (not a dot), [^\W] after the @ sign to prevent non-alphanumeric characters from being accepted, as well as another [^.] before the last dot to prevent a double dot just before the extension.
This fixed a number of problems with the original RegEx, but it was just becoming more and more convoluted:
^[^\W]([a-z0-9_.-]+)[^.]@([^\W][\da-z.-]+)([^.]\.[a-z]{2,6}[^\W])$
Plus there was still a problem with double dots appearing almost anywhere else within the RegEx. Rather, than proceeding further with this one, it's time to switch directions and look at the RegEx e-mail address validation I used with the ComputorEdge Web subscriptions form:
^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,4})+$
It turns out that this expression does a much better job with e-mail addresses. There is one significant difference which makes it work much better which I'll highlight.
The moral of the story is, "Don't expect that a RegEx you find on the Web will work as advertised." There are many ways to do the same thing, but some are simpler and more effective. Check out a RegEx by testing it before using it. (Ryan's RegEx Tester is exceptional for this type of testing. Change your input string and see immediate results.)
The Second Approach to Validating E-mail Addresses
Above, I took a look at a Regular Expression (RegEx) I found on the Web for ensuring that an e-mail address was properly formatted. As it turned out, there were a lot of problems with that expression. I then introduced the RegEx that is used by the ComputorEdge E-mail Subscription form. It was many years ago when I added this JavaScript RegEx to the Web page and I know that there were changes made, but originally I must have copied it from somewhere. What surprised me in my current AutoHotkey RegEx studies is both how clean the expression is and how well it works. In addition, deciphering this expression turned a corner for me in my understanding of RegEx. It gave me a glimpse into the power of RegEx and its numerous possibilities. If you're one of the few who has hung in there while digging into the mysteries of AutoHotkey RegEx techniques, then I hope to pass on some valuable insights.
ComputorEdge Subscription Form Validation RegEx
It's worthwhile to take a look at the e-mail address format RegEx used by the ComputorEdge Subscription Form:
^\w+([\.-]?\w+)*@\w+([\.-]?\w+)*(\.\w{2,4})+$
There are a couple of features used in this RegEx which show its power. As noted above, I was having trouble dealing with the dots (.) in an e-mail address. The RegEx I had copied allowed extra dots in the bad locations and double dots (..) almost anywhere. As I tried to resolve the problems, the expression became longer and more confusing. This new RegEx solved all the problems and simplified the code. When I plugged it into Ryan's RegEx tester (introduced in Chapter One), it became clear how it worked. It was the clever use of subpatterns as designated by expressions enclosed in parentheses that did the job.
I have seen parentheses used in a RegEx, but often they serve no real purpose. For example, the first e-mail validation RegEx contained a few sets of parentheses, but they could be removed without any impact on the results. They were gratuitously inserted probably to help the programmer see key elements. (To be fair, if you insert the original RegEx from last week into Ryan's RegEx Tester, you will see that the portions of the e-mail address are broken out (name, domain, extension) which may be used for other purposes. By the time I finished with that expression, even that value was lost. Plus, parentheses can be used to designate order of evaluation for an expression.)
When a portion of a RegEx is enclosed with a set of parentheses, it creates a subpattern which can be repeated or used as a backreference with the RegExReplace() function. (Consult the AutoHotkey RegEx Quick Reference for options.) Just as a key concept in writing a RegEx is designating a class (or range) by enclosing characters in square brackets […], it's important to understand subpatterns as designated by enclosing expressions in a set of parentheses (…).
Using the symbols *, +, ?, or {min,max} after a subpattern (in this example ([\.-]?\w+)*) causes the entire subpattern to be matched: zero or more times, (subpattern)*; one or more times, (subpattern)+; zero or one time only, (subpattern)?; or a minimum and maximum number of times, (subpattern){min,max}. This extends the power of RegEx.
In this first subpattern, the range or class enclosed in the square brackets, [\.-], consists of the dot and hyphen. Either constitutes a match. By adding the question mark to the range, [\.-]?, the class becomes optional (match zero or one time). Next the \w symbol is used to indicate that any letter (upper or lowercase) or digit, plus the underline mark is an acceptable match (equivalent to [a-zA-Z0-9_]). Adding the plus sign, \w+, means continue matching until it doesn't match. Ultimately, adding the asterisks to the subpattern, ([\.-]?\w+)*, tells the RegEx to continue matching the subpattern until it doesn't match the entire subpattern. The effect of this subpattern is to continue to allow segments starting with either a dot or hyphen (not two in a row or both) to be matched in the first section of any e-mail address as shown in Figure 2.

Figure 2. Ryan's Regular Expression Tester is used to evaluate the e-mail address validating expression used by the ComputorEdge E-mail Subscription Form.
Note that when placed in the RegExMatch tab of the Ryan Tester, Match[1] in the Results section only shows the last match, .publisher. for the subpattern. As each new match is made only the last subpattern match is saved in the array for possible reference. When the @ symbol is encountered (once only) in the string, RegEx moves on.
At this point it is worth noting that this RegEx is anchored, ^, at the beginning with ^\w+ which forces at least the first character (plus any other following characters, +, until a dot or hyphen in the subpattern is encountered) to match only a letter (upper or lowercase), numeric digit, or the underline mark. This same expression is used after the @ symbol for the same purpose. This prevents random dots and other illegal symbols matching in e-mail addresses.
The second subpattern, ([\.-]?\w+)*, which appears in the second half of the RegEx (after the @) is identical to the first subpattern and serves the same purpose. It allows the repeating of matches which start with a dot or hyphen.
The last subpattern, (\.\w{2,4}), is anchored with $ at the end of the string, (\.\w{2,4})+$. This forces the end of the e-mail address to start with a dot (no hyphen this time), then accept letters (upper or lowercase), or numeric digits but only two to four characters, {2,4}. The last plus sign + can be removed since the \w+ in the previous subpattern makes it superfluous. If you play with Ryan's RegEx Tester, you will quickly find out which pieces of the expression are important and which are unneeded clutter.
One last note about unneeded characters in an AutoHotkey RegEx. The dot is normally a wildcard which can represent any single character in any RegEx. However, within a class (or range) designated by the square brackets the dot is not a wildcard, but just a dot. With the exception of characters with special meaning inside the square brackets, such as ^ and \, an escape sequence is not required. That means in our example the dot found inside the square brackets in the first and second subpattern is merely a dot and not a wildcard. The backslash serves no purpose here and can be removed. This is not the case for the dot in the last subpattern where it acts as a wildcard if the escape backslash is removed.
The final expression can be reduced to:
^\w+([.-]?\w+)*@\w+([.-]?\w+)*(\.\w{2,4})$
There are a number of uses for parentheses in a RegEx. (Examples of those other uses of parentheses can be found in the AutoHotkey RegEx Quick Reference.)
Creating subpatterns which are saved to an array is one of the most powerful features of RegEx. In Chapter Three, "Using RegExReplace() to Add AutoHotkey Escape Characters", I looked at how subpatterns can be used as backreferences with the RegExReplace() function and tested in the RegExReplace tab of Ryan's RegEx Tester.
I've compiled Ryan's RegEx Tester into an EXE file and included both the AHK file and EXE in a ZIP file for download at theComputorEdge AutoHotkey download site.
In the next chapter, we look at using backreferences with RegExReplace().
Chater Twelve: Look-Ahead and Look-Behind RegEx Mysteries
“Look in front of and behind the Haystack for RegEx signposts to create a match.”
A look at the confusing world of look-ahead and look-behind assertions in AutoHotkey RegEx. See how they can extend the power of Regular Expressions.
Look-Ahead and Look-Behind Assertions in AutoHotkey Regular Expressions (RegEx)
Look-ahead and look-behind assertions in AutoHotkey Regular Expressions (RegEx) is not a topic for the faint of heart. It took me a while to wrap my brain around this one, but I can see some practical applications for them. If you check out the AutoHotkey RegEx Quick Reference, you will see "Look-ahead and look-behind assertions" discussed toward the end of the page. I had to do additional digging and testing, but there are definitely worthwhile uses for these operators. The examples I use only offer a glimpse into the possibilities when included in an AutoHotkey script.
To understand look-ahead and look-behind assertions, we need to remember how the RegEx engine works. It starts at the left end of a text string and proceeds to the right while looking for matches. That means if RegEx is looking ahead, it is looking to the right of the current match. If RegEx is looking behind, it is looking to the left of the current match. These look-ahead and look-behind expressions do not become part of the match nor save any characters. Look-ahead is merely another way of saying, "If you can see a particular pattern ahead (to the right), then the match is valid—even though that pattern is not part of the match." Look-behind is another way of saying, "If you can see a particular pattern behind (to the left), then the match is valid—even though that pattern is not part of the match."
Each look-ahead and look-behind assertion also can be negative, meaning the pattern is not ahead or the pattern is not behind respectively. The look-behind assertion is more limited since the wildcards (*, +, and ?) cannot be used.
To test and demonstrate these expressions, I used Robert Ryan's RegEx Tester This RegEx Tester is one of the best ways to play with a RegEx. As you make changes to the expression the results instantly appear in the lower pane. Once the RegEx is working, simply copy-and-paste it into the RegExMatch() function or the RegExReplace() function in your AutoHotkey script. (Remember, if there are any double quote marks in the RegEx, they will need to be escaped in the function with another preceding double quote mark.)
The text used in these examples was simply copied (CTRL+C) from this City Data page and pasted (CTRL+V) into the top pane of Ryan's RegEx Tester (see Figure 3).
How Look-ahead Assertions Work
Each assertion is composed of a set of parentheses with a question mark as the first character inside. (This is yet another usage of parentheses and the question mark.) The look-ahead assertion takes the form (?=...) and always follows the primary expression, e.g. (\w[\w\s]+)(?=, California). Notice the equal sign following the question mark. This tells RegEx that the main expression must be followed by a comma, a space, and the word "California" to return a valid match as shown in Figure 1.

Figure 1. This look-ahead assertion finds a city in California.
The RegEx used in this Figure 3 is:
(\w[\w\s]+)(?=, California)
The primary part of the expression (\w[\w\s]+) must start with any letter or digit \w and will continue matching letters, digits, or spaces \s until something else is encountered—in this case a comma. But the match is only valid (?=, California) if it is followed by a comma, space and the word "California" combination. However, since the match starts at position 87 (circled in Figure 3), Los Angeles is skipped returning San Diego.
If used in an AutoHotkey script, California cities could be extracted from the text by placing the RegExMatch() function inside a Loop and incrementing the starting position to a point past the last match. Examples of this Loop technique appear in previous chapters.
The same matching can be done with two sub-expressions:
(\w[\w\s]+), (California)
but the word California would be retained in the match—which depending upon what you're trying to accomplish is not necessarily bad. The look-ahead assertion automatically dumps the word California from each match.
How Negative Look-ahead Assertions Work
The negative look-ahead assertion takes the form (?!...) and always follows the primary expression, e.g. (\w[\w\s]+)(?!, California). The equal sign is replaced with the not ! operator making the expression a negative, as shown in Figure 2.

Figure 2. This look-ahead assertion finds a city not in California.
By making the expression a negative:
(\w[\w\s]+)(?!, California)
RegEx looks for the first match which is not followed by a comma, space and the word California. This would be useful for an AutoHotkey script which list cities that are not in California. In this case, it's unlikely that you would want to capture the look-ahead expression since it is a negative and by definition missing.
How Look-behind Assertions Work
The primary difference between the look-ahead assertions (which always follows the main expression) and the look-behind assertions (which always preceded the main expression) is a left arrow (or arrow bracket) inserted just after the question mark (?<=...) indicating that the RegEx must look back or to the left, e.g. (?<=8.\t\s)([\w\s]+), as shown in Figure 3.

Figure 3. This look-behind assertion finds the eight (number 8) city on the list.
In this case the RegEx:
(?<=8.\t\s)([\w\s]+)
finds the city which is ranked eighth (8) on the list. For the match to be valid, the main expression ([\w\s]+) which can be any continuous set of letters, digits, or spaces must be preceded ?<= by the number 8, any character (here the . represents any character), a tab \t, and a space \s. This only works for number 8 on the list. Change the number and a different city will be found. (To force the . to represent a period it must be escaped \. by placing a backslash in front of it.)
There is another operator \K which acts in a manner similar to the look-behind assertion. The RegEx demands that the portion before the \K be matched, but it is not included in the match, as shown in Figure 4.

Figure 4. The \K escape sequence acts like a look-behind assertion returning the number eight (8) city on the list.
The primary difference when using the \K is the look-behind values can be saved as a sub-expression:
(8.)\t\s\K([\w\s]+)
By placing the desired portion of the look-behind in parentheses, it becomes the first backreference. While the total Match would remain only San Antonio, Match[1] would be 8. and Match[2] would be San Antonio. This adds a little more flexibility to the look-behind assertion, plus, unlike the standard look-behind assertion (?<=...) the wildcard operators *, +, and ? can be used with the \K operator.
How Negative Look-behind Assertions Work
The negative look-behind assertion takes the form (?<!...) and always precedes the primary expression, e.g. (?<!Los Angeles, )(California .*?\)). The equal sign is replaced with the not ! operator making the expression a negative, as shown in Figure 5.

Figure 5. This look-behind assertion finds the first California city and population which is not Los Angeles.
In the example the RegEx:
(?<!Los Angeles, )(California .*?\))
is looking for the first California city which is not Los Angeles (?<!Los Angeles, ). When California is followed by the first closing parentheses \) (the ")" must be escaped with a backslash \), the RegEx looks back for the words Los Angeles. If found, the match is ruled invalid and RegEx continues to the next match—in this case the San Diego listing
Look-ahead and look-behind assertions can be confusing, but they are important tools in your AutoHotkey RegEx toolbox. The time might come when you need to include (or exclude) specific patterns from matches without making the evaluation part of the match. That's when these techniques will make easy work of it.
Chapter Thirteen: Using RegEx Property Symbols
“RegEx Properties \\p{xx} extend the flexibility of Regular Expressions.”
Use properties (\\p{xx}) in AutoHotkey RegEx to correct punctuation, change currency symbols, and remove sets of brackets and parentheses.
Using Properties (\p) with AutoHotkey Regular Expressions (RegEx)
In this chapter we take a look at RegEx properties which are called by the operator \p. The various \p options are not listed in the AutoHotkey documentation, but there are many places on the Web where they are discussed. In this chapter we show at a few ways that properties can be used and include a list of some of the most useful options.
A property is called in a RegEx by inserting \p{xx}. The \p tells RegEx to use the property designated by the characters within the following curly brackets {xx}. For example, \p{P} tells RegEx to look for any kind of punctuation. This could be used to correct typographic errors as shown in Figure 1. In this case, any word (as bounded by \b) with any punctuation inside it will change that punctuation to an apostrophe. (Ryan's RegEx Tester is used to demonstrate the effect of RegEx Properties (\p{xx}).

Figure 1. This RegEx finds words with any punctuation inside and replaces the punctuation with an apostrophe
The RegEx is fairly straightforward:
i)\b(\w+)\p{P}(\w+)\b
The i) option at the beginning tells RegEx says to ignore the case of any letters. Surrounding the RegEx with \b will ensure that only single words are matched. The first sub-pattern (\w+) as designated by the first set of parentheses tells RegEx to match one or more letters or digits. Next, any punctuation mark can match \p{P} followed again by one or more letters or digits (\w+).
Since we don't expect digits in any of our target words, a better RegEx would be:
i)\b([A-Z]+)\p{P}([A-Z]+)\b
This limits the possible characters to letters—upper or lower case as allowed by the i) option. However, this RegEx will only be useful when there are no other uses of punctuation inside a word. URL with dots or underscores would change the first occurrence to an apostrophe.
Since this is merely a demonstration of how \p{xx} works we'll move on to other examples. If you actually wanted to fix contraction typos, you would probably be better off listing the worrisome characters:
i)\b([A-Z]+)[;;,]([A-Z]+)\b
This eliminates the use of \p{xx} but makes the expression more narrowly targeted.
The Currency Symbol Property
There is a RegEx property which matches any symbol, \p{S}. To match only currency symbols, the expression is \p{Sc} (see Figure 2). This might come in handy if you need to either find any mention of currencies or replace all dollars with British pounds.

Figure 2. Any currency symbol is matched and replaced with the British ?.
Notice how every currency symbol whether dollar, yen, or cents was matched (and replaced with the ? symbol) by \p{Sc}.
Removing Parentheses and Brackets
Figure 3. Parentheses, curly brackets and square brackets are removed by using \p{Ps} and \p{Pe} respectively.
These examples are used only to demonstrate how the properties can be called and how they work. It is up to the script writer to determine when they may be most useful and how to implement them. Make sure that you're using the current version of AutoHotkey since \p is supported in AutoHotkey 1.1 (AutoHotkey_L) versions.
Most Useful RegEx Properties
The following is a list of RegEx properties I found the most useful. For a complete list, see www.pcre.org/pcre.txtand search for \p{xx}.
P Punctuation \p{P}: any kind of punctuation character.
Pc Connector punctuation \p{Pc}: a punctuation character such as an underscore that connects words.
Pd Dash punctuation \p{Pd}: any kind of hyphen or dash.
Pe Close punctuation \p{Pe}: any kind of closing bracket.
Pf Final punctuation \p{Pf}: any kind of closing quote.
Pi Initial punctuation \p{Pi}: any kind of opening quote.
Po Other punctuation \p{Po}: any kind of punctuation character that is not a dash, bracket, quote or connector.
Ps Open punctuation \p{Ps}: any kind of opening bracket.
Pc Connector punctuation \p{Pc}: a punctuation character such as an underscore that connects words.
Pd Dash punctuation \p{Pd}: any kind of hyphen or dash.
Pe Close punctuation \p{Pe}: any kind of closing bracket.
Pi Initial punctuation \p{Pi}: any kind of opening quote.
Po Other punctuation \p{Po}: any kind of punctuation character that is not a dash, bracket, quote or connector.
Ps Open punctuation \p{Ps}: any kind of opening bracket.
S Symbol \p{S}: math symbols, currency signs, dingbats, box-drawing characters, etc.
Sc Currency symbol \p{Sc}: any currency sign.
Sk Modifier symbol \p{Sk}: a combining character (mark) as a full character on its own.
Sm Mathematical symbol \p{Sm}: any mathematical symbol.
So Other symbol \p{So}: various symbols that are not math symbols, currency signs, or combining characters.
Sc Currency symbol \p{Sc}: any currency sign.
Sk Modifier symbol \p{Sk}: a combining character (mark) as a full character on its own.
Sm Mathematical symbol \p{Sm}: any mathematical symbol.
So Other symbol \p{So}: various symbols that are not math symbols, currency signs, or combining characters.
L Letter \p{L} or \p{Letter}: any kind of letter from any language.
Ll Lower case letter \p{Ll} or \p{Lowercase_Letter}: a lowercase letter that has an uppercase variant.
Lm Modifier letter \p{Lm} or \p{Modifier_Letter}: a special character that is used like a letter.
Lo Other letter \p{Lo} or \p{Other_Letter}: a letter or ideograph that does not have lowercase and uppercase variants.
Lt Title case letter \p{Lt}: a letter that appears at the start of a word when only the first letter of the word is capitalized.
Lu Upper case letter \p{Lu}: an uppercase letter that has a lowercase variant.
Ll Lower case letter \p{Ll} or \p{Lowercase_Letter}: a lowercase letter that has an uppercase variant.
Lm Modifier letter \p{Lm} or \p{Modifier_Letter}: a special character that is used like a letter.
Lo Other letter \p{Lo} or \p{Other_Letter}: a letter or ideograph that does not have lowercase and uppercase variants.
Lt Title case letter \p{Lt}: a letter that appears at the start of a word when only the first letter of the word is capitalized.
Lu Upper case letter \p{Lu}: an uppercase letter that has a lowercase variant.
N Number \p{N}: any kind of numeric character in any script.
Nd Decimal number \p{Nd}: a digit zero through nine in any script except ideographic scripts.
Nl Letter number \p{Nl}: a number that looks like a letter, such as a Roman numeral.
No Other number \p{No}: a superscript or subscript digit, or a number that is not a digit 0?9 (excluding numbers from ideographic scripts).
Nd Decimal number \p{Nd}: a digit zero through nine in any script except ideographic scripts.
Nl Letter number \p{Nl}: a number that looks like a letter, such as a Roman numeral.
No Other number \p{No}: a superscript or subscript digit, or a number that is not a digit 0?9 (excluding numbers from ideographic scripts).
Z Separator \p{Z}: any kind of whitespace or invisible separator.
Zl Line separator \p{Zl}: line separator character U+2028.
Zp Paragraph separator \p{Zp}: paragraph separator character U+2029.
Zs Space separator \p{Zs}: a whitespace character that is invisible, but does take up space.
Zl Line separator \p{Zl}: line separator character U+2028.
Zp Paragraph separator \p{Zp}: paragraph separator character U+2029.
Zs Space separator \p{Zs}: a whitespace character that is invisible, but does take up space.
Index to Chapters
“Index to chapters for key terms.”
$ end or terminating anchor;Chapter Four;Chapter Eleven
(…) order of evaluation, capture special features, or change options;Chapter Eleven
* Match preceding 0 or more times;Chapter Eleven
^ Do not match inside a range [^…];Chapter Four
^ Front end or beginning anchor;Chapter Four;Chapter Eleven
^ Circumflex;Chapter Four
^\d. Exclude all digits and decimal points;Chapter Four
^ Do not match inside a range [^…];Chapter Four
^ Front end or beginning anchor;Chapter Four;Chapter Eleven
^ Circumflex;Chapter Four
^\d. Exclude all digits and decimal points;Chapter Four
. (dot) is the wildcard for any character;Chapter Two;Chapter One
. (dot) as a decimal point or period;Chapter Two
.*? Question mark to eliminate greed;Chapter Nine
. (dot) as a decimal point or period;Chapter Two
.*? Question mark to eliminate greed;Chapter Nine
(?!, California) Negative look-ahead assertion;Chapter Twelve
(?<!Los Angeles, ) Negative look-behind assertion;Chapter Twelve
(?<=...) Look-behind assertion;Chapter Twelve
(?=, California) Look-ahead assertion;Chapter Twelve
? Look-ahead and look-behind assertions;Chapter Twelve
? Negative look-ahead assertion (?!, California);Chapter Twelve
? Optional expressions \S?;Chapter Seven
? Optional match;Chapter Four;Chapter Eleven
? Question mark to eliminate greed .*?;Chapter Nine
?: Do not capture subpattern inside (?:…);Chapter Eight
(?<!Los Angeles, ) Negative look-behind assertion;Chapter Twelve
(?<=...) Look-behind assertion;Chapter Twelve
(?=, California) Look-ahead assertion;Chapter Twelve
? Look-ahead and look-behind assertions;Chapter Twelve
? Negative look-ahead assertion (?!, California);Chapter Twelve
? Optional expressions \S?;Chapter Seven
? Optional match;Chapter Four;Chapter Eleven
? Question mark to eliminate greed .*?;Chapter Nine
?: Do not capture subpattern inside (?:…);Chapter Eight
[^\W] Prevent non-alphanumeric matches;Chapter Eleven
[…] Ranges;Chapter Two
[0-9]+ Repeated range;Chapter Four
[a-z0-9_\.-] Any lowercase letters, numbers, the underline mark, dots, and hyphens;Chapter Eleven
[a-zA-Z0-9] All letters and numeric digits;Chapter Two
[…] Ranges;Chapter Two
[0-9]+ Repeated range;Chapter Four
[a-z0-9_\.-] Any lowercase letters, numbers, the underline mark, dots, and hyphens;Chapter Eleven
[a-zA-Z0-9] All letters and numeric digits;Chapter Two
\ Backslash not required within range to escape dot .;Chapter Eleven
\ Backslash, escape character;Chapter Two
\. Dot escape sequence;Chapter Two;Chapter Eleven
\b Word match boundary;Chapter Five;Chapter Thirteen
\d Same as [0-9] or [0123456789];Chapter Two;Chapter Four;Chapter Eleven
\d{1,3} 0 to 9 at least once no more than three times;Chapter Eight
\K Look behind assertion;Chapter Twelve
\p{P} Match any punctuation;Chapter Thirteen
\p{Pe} Match end or close bracket or parenthesis;Chapter Thirteen
\p{Ps} Match start or open bracket or parenthesis;Chapter Thirteen
\p{S} Match any symbol;Chapter Thirteen
\p{Sc} Match any currency symbol;Chapter Thirteen
\p{xx} Properties;Chapter Thirteen
\s Space;Chapter Five
\W any non-alphanumeric character;Chapter Eleven
\w Match any letter or digit, [a-zA-Z0-9];Chapter Thirteen;Chapter Four;Chapter Two
\ Backslash, escape character;Chapter Two
\. Dot escape sequence;Chapter Two;Chapter Eleven
\b Word match boundary;Chapter Five;Chapter Thirteen
\d Same as [0-9] or [0123456789];Chapter Two;Chapter Four;Chapter Eleven
\d{1,3} 0 to 9 at least once no more than three times;Chapter Eight
\K Look behind assertion;Chapter Twelve
\p{P} Match any punctuation;Chapter Thirteen
\p{Pe} Match end or close bracket or parenthesis;Chapter Thirteen
\p{Ps} Match start or open bracket or parenthesis;Chapter Thirteen
\p{S} Match any symbol;Chapter Thirteen
\p{Sc} Match any currency symbol;Chapter Thirteen
\p{xx} Properties;Chapter Thirteen
\s Space;Chapter Five
\W any non-alphanumeric character;Chapter Eleven
\w Match any letter or digit, [a-zA-Z0-9];Chapter Thirteen;Chapter Four;Chapter Two
`n for newline or linefeed;Chapter Five
`r for carriage return;Chapter Five
`r for carriage return;Chapter Five
{2,6} min two and max six of preceding range;Chapter Eleven
{min,max} Match preceding at least min and no more than max times;Chapter Four;Chapter Six;Chapter Seven;Chapter Eight;Chapter Eleven
{min,max} Match preceding at least min and no more than max times;Chapter Four;Chapter Six;Chapter Seven;Chapter Eight;Chapter Eleven
+ Match preceding 1 or more times;Chapter Two;Chapter Five;Chapter Eleven
+ Similar to the star *, but is used to match one or more;Chapter One
+ Similar to the star *, but is used to match one or more;Chapter One
<a href="URL">Link Text</a>;Chapter Ten
Alternative matches;Chapter Seven
AutoHotkey Forum;Chapter Eight
AutoHotkey_L RegEx Tester (Ryan's);Chapter One
AutoHotkey_L support;Chapter Thirteen
AutoHotkey Forum;Chapter Eight
AutoHotkey_L RegEx Tester (Ryan's);Chapter One
AutoHotkey_L support;Chapter Thirteen
Backreference;Chapter Six;Chapter Seven;Chapter Eight;Chapter Eleven
Backreference as replacement;Chapter Five
Backreference in the expression;Chapter Five
Backreference to make the match;Chapter Five
Break;Chapter Eight
Backreference as replacement;Chapter Five
Backreference in the expression;Chapter Five
Backreference to make the match;Chapter Five
Break;Chapter Eight
Case insensitive option;Chapter Five
Changing and rearranging data, RegExReplace();Chapter One
Circumflex ^ different meanings;Chapter Four
Clipboard := SubStr(Clipboard,2);Chapter Seven
ClipWait command;Chapter Seven;Chapter Eight
ComObjCreate("WinHttp.WinHttpRequest.5.1");Chapter Eight
ComObjCreate() function;Chapter Eight
Contractions, fix multiple errors;Chapter Six
CountIP++;Chapter Eight
Changing and rearranging data, RegExReplace();Chapter One
Circumflex ^ different meanings;Chapter Four
Clipboard := SubStr(Clipboard,2);Chapter Seven
ClipWait command;Chapter Seven;Chapter Eight
ComObjCreate("WinHttp.WinHttpRequest.5.1");Chapter Eight
ComObjCreate() function;Chapter Eight
Contractions, fix multiple errors;Chapter Six
CountIP++;Chapter Eight
Dot (.) not used inside a range;Chapter Two
Dot (.) used inside a range;Chapter Two
Duplicate words in text;Chapter Five
Dot (.) used inside a range;Chapter Two
Duplicate words in text;Chapter Five
Eliminate loops when possible;Chapter Ten
Eliminating extra spaces;Chapter Five
E-mail address validation;Chapter Eleven
Extracting and replicating data, RegExMatch();Chapter One
Extracting IP addresses;Chapter Eight
Extracting, Web links from a Web page;Chapter Ten
Eliminating extra spaces;Chapter Five
E-mail address validation;Chapter Eleven
Extracting and replicating data, RegExMatch();Chapter One
Extracting IP addresses;Chapter Eight
Extracting, Web links from a Web page;Chapter Ten
FileAppend command;Chapter Nine;Chapter Ten
FileDelete command;Chapter Nine;Chapter Ten
FileRead command;Chapter Nine;Chapter Ten
Forcing a number type from a string;Chapter Four
FoundPos;Chapter Two
FileDelete command;Chapter Nine;Chapter Ten
FileRead command;Chapter Nine;Chapter Ten
Forcing a number type from a string;Chapter Four
FoundPos;Chapter Two
Greed;Chapter Nine
Haystack;Chapter Two
History of Regular Expressions;Chapter One
How RegEx Works;Chapter Two
HTML language;Chapter Nine
HTML source code, stripping out;Chapter Nine
HTML tags;Chapter Ten
HTTP(S):// RegEx;Chapter Ten
History of Regular Expressions;Chapter One
How RegEx Works;Chapter Two
HTML language;Chapter Nine
HTML source code, stripping out;Chapter Nine
HTML tags;Chapter Ten
HTTP(S):// RegEx;Chapter Ten
i) Option, ignore case;Chapter Thirteen
InStr() function;Chapter Seven
IP address matching;Chapter Eight
InStr() function;Chapter Seven
IP address matching;Chapter Eight
Kleene plus +;Chapter One
Kleene star *;Chapter One
Kleene star *;Chapter One
Line continuation;Chapter Seven
List of useful RegEx properties \p{xx};Chapter Thirteen
Locate duplicate words;Chapter Five
Look-ahead assertions;Chapter Twelve
Look-behind assertions;Chapter Twelve
Loop command;Chapter Eight;Chapter Ten
Loop, using RegExMatch() in;Chapter Two
List of useful RegEx properties \p{xx};Chapter Thirteen
Locate duplicate words;Chapter Five
Look-ahead assertions;Chapter Twelve
Look-behind assertions;Chapter Twelve
Loop command;Chapter Eight;Chapter Ten
Loop, using RegExMatch() in;Chapter Two
Mark double words;Chapter Five
Matching contractions;Chapter Five
Matching more than one IP address;Chapter Eight
Matching the end of a string;Chapter Four
Matching words only;Chapter Five
MatchObject;Chapter Five;Chapter Eight;Chapter Eleven
Matching contractions;Chapter Five
Matching more than one IP address;Chapter Eight
Matching the end of a string;Chapter Four
Matching words only;Chapter Five
MatchObject;Chapter Five;Chapter Eight;Chapter Eleven
Needle in a haystack;Chapter Two
NeedleRegEx;Chapter Two
Non-greedy mode;Chapter Ten
Numeric digit wildcard (\d);Chapter Three
Numeric location in Haystack;Chapter Two
NeedleRegEx;Chapter Two
Non-greedy mode;Chapter Ten
Numeric digit wildcard (\d);Chapter Three
Numeric location in Haystack;Chapter Two
O) MatchObject Option;Chapter Five;Chapter Eight;Chapter Eleven
Object Oriented Programming (OOP);Chapter Five
Object properties;Chapter Five
Optional \S? expressions;Chapter Seven
Object Oriented Programming (OOP);Chapter Five
Object properties;Chapter Five
Optional \S? expressions;Chapter Seven
P) Position Option;Chapter Five
Parse a number from the title of a window;Chapter Three
Properties, using in RegEx \p{xx};Chapter Thirteen
Pseudo-array;Chapter Eight
Punctuation mark, match;Chapter Thirteen
Parse a number from the title of a window;Chapter Three
Properties, using in RegEx \p{xx};Chapter Thirteen
Pseudo-array;Chapter Eight
Punctuation mark, match;Chapter Thirteen
Ranges in RegEx matches[…];Chapter Three;Chapter Two
Reference online RegEx;Chapter Two
Reformatting data, RegExReplace();Chapter Three
RegEx history;Chapter One
RegEx Options;Chapter Five
RegEx Quick Reference;Chapter Two
RegEx Tester (Robert Ryan);Chapter Three;Chapter Eight
RegEx Tester script;Chapter One
RegEx Tester using;Chapter Five
RegExMatch() and RegExReplace(), differences and uses;Chapter Two
RegExMatch() for extracting data;Chapter Three
RegExMatch() function;Chapter One;Chapter Two;Chapter Three;Chapter Four;Chapter Eight;Chapter Eleven
RegExMatch() is for mining, extracting, and replicating data;Chapter One
RegExMatch(), using in Loop;Chapter Two
RegExReplace();Chapter Two
RegExReplace();Chapter One
RegExReplace() for correcting data;Chapter Three
RegExReplace() for reformatting data;Chapter Three
RegExReplace() is for changing and rearranging;Chapter One
RegExReplace();Chapter One;Chapter Three;Chapter Four;Chapter Seven;Chapter Nine
Regular Expression testing app;Chapter One
Regular Expressions (RegEx or RegExp);Chapter Two
Remove all non-numeric characters;Chapter Three
Remove all of the letters (upper and lowercase) in a variable;Chapter Four
Removing unwanted characters;Chapter Four
Repeated expression in parentheses;Chapter Eight
Retrieval of Web page data;Chapter Eight
Retrieve IPs geographic location;Chapter Eight
Run command;Chapter Nine;Chapter Ten
Ryan's Regular Expression testing app;Chapter One
Reference online RegEx;Chapter Two
Reformatting data, RegExReplace();Chapter Three
RegEx history;Chapter One
RegEx Options;Chapter Five
RegEx Quick Reference;Chapter Two
RegEx Tester (Robert Ryan);Chapter Three;Chapter Eight
RegEx Tester script;Chapter One
RegEx Tester using;Chapter Five
RegExMatch() and RegExReplace(), differences and uses;Chapter Two
RegExMatch() for extracting data;Chapter Three
RegExMatch() function;Chapter One;Chapter Two;Chapter Three;Chapter Four;Chapter Eight;Chapter Eleven
RegExMatch() is for mining, extracting, and replicating data;Chapter One
RegExMatch(), using in Loop;Chapter Two
RegExReplace();Chapter Two
RegExReplace();Chapter One
RegExReplace() for correcting data;Chapter Three
RegExReplace() for reformatting data;Chapter Three
RegExReplace() is for changing and rearranging;Chapter One
RegExReplace();Chapter One;Chapter Three;Chapter Four;Chapter Seven;Chapter Nine
Regular Expression testing app;Chapter One
Regular Expressions (RegEx or RegExp);Chapter Two
Remove all non-numeric characters;Chapter Three
Remove all of the letters (upper and lowercase) in a variable;Chapter Four
Removing unwanted characters;Chapter Four
Repeated expression in parentheses;Chapter Eight
Retrieval of Web page data;Chapter Eight
Retrieve IPs geographic location;Chapter Eight
Run command;Chapter Nine;Chapter Ten
Ryan's Regular Expression testing app;Chapter One
Saving RegEx matches to a variable;Chapter Two
SendInput, ^c;Chapter Seven
SetFormat command;Chapter Four
Sleep command to delay script execution;Chapter Eight
StringGetPos command;Chapter Seven
StringReplace command;Chapter Nine
StringTrimRight;Chapter Three
Stripping out HTML code;Chapter Nine
StrLen() function;Chapter Eight
Sub-pattern
Subpattern (…);Chapter Ten;Chapter Eleven
Sub-reference;Chapter Ten
SubStr() function;Chapter Four;Chapter Seven
SubStr(Clipboard,1,1);Chapter Seven
Swapping contractions in text;Chapter Seven
Swapping letters in text;Chapter Seven
Swapping two words in text;Chapter Seven
SendInput, ^c;Chapter Seven
SetFormat command;Chapter Four
Sleep command to delay script execution;Chapter Eight
StringGetPos command;Chapter Seven
StringReplace command;Chapter Nine
StringTrimRight;Chapter Three
Stripping out HTML code;Chapter Nine
StrLen() function;Chapter Eight
Sub-pattern
Subpattern (…);Chapter Ten;Chapter Eleven
Sub-reference;Chapter Ten
SubStr() function;Chapter Four;Chapter Seven
SubStr(Clipboard,1,1);Chapter Seven
Swapping contractions in text;Chapter Seven
Swapping letters in text;Chapter Seven
Swapping two words in text;Chapter Seven
Test script, Ryan's;Chapter Two
Testing a RegEx;Chapter Eleven
Testing RegEx, a simple script;Chapter Eleven
Testing a RegEx;Chapter Eleven
Testing RegEx, a simple script;Chapter Eleven
UrlDownloadToFile command;Chapter Eight;Chapter Nine;Chapter Ten
Web links from a Web page, extracting;Chapter Ten
Web to retrieve the IP's geographic location;Chapter Eight
Wildcard, dot (.);Chapter Eight
Word boundary \b;Chapter Five
Web to retrieve the IP's geographic location;Chapter Eight
Wildcard, dot (.);Chapter Eight
Word boundary \b;Chapter Five
Комментариев нет:
Отправить комментарий